The RDO community is pleased to announce the general availability of the RDO build for OpenStack 2024.1 Caracal for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Caracal is the 29th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The release is already available for CentOS Stream 9 on the CentOS mirror network in:
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud SIG. The Cloud SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
Drivers with inactive CI were marked unsupported including Windows iSCSI Driver, Windows SMB Driver, Dell SC Series Storage Driver (iSCSI, FC), Dell VNX Storage Driver (FC, iSCSI) and Dell XtremeIO Storage Driver (iSCSI, FC).
New driver features were added, notably, Fujitsu ETERNUS DX extend volume on RAID group, Pure Storage synchronous replication, NetApp iSCSI LUN space allocation, Dell PowerFlex Active-Active support, Dell PowerMax configurable SRDF snapshots.
Designate now supports Catalog Zones (RFC 9432). This can improve the scalability of Designate pools managing a large number of zones and significantly reduce the provisioning time when adding additional DNS servers to a Designate pool.
Horizon now uses Django 4.2 as default and dropped Django 3.2 support.
Ironic has enabled RBAC support by default by changing the default values of [oslo_policy]enforce_scope and [oslo_policy]enforce_new_defaults to True. Additionally, we added [DEFAULT]rbac_service_project_name to define a project where users in that project are treated as having a service role. Please see Ironic release notes for full details.
Ironic has added the ability to drain active tasks from a conductor before shutdown. Sending a SIGUSR2 signal to an ironic-conductor will now attempt to complete running tasks with a timeout of [DEFAULT]drain_shutdown_timeout. No new tasks will be started on the conductor while it’s draining.
Support was added for the external-gateway-multihoming API extension. The L3 service plugins supporting it can now create multiple gateway ports per router. It is currently limited to the L3 OVN plugin.
RDO Caracal 2024.1 has been built and tested with the recently released Ceph 18.2.0 Reef version (https://docs.ceph.com/en/latest/releases/reef/) which has been published by the CentOS Storage SIG in the official CentOS repositories. *Note:* Follow the instructions in [RDO documentation](https://www.rdoproject.org/install/install-with-ceph/) to install OpenStack and Ceph services in the same host.
During Caracal cycle, some projects have been retired or declared inactive upstream.As such, the following packages for some projects are not present in the RDO Caracal 2024.1 release:
cinderlib
dib-utils
ec2api-tempest-plugin
ec2api
murano
murano-agent
muranoclient
murano-dashboard
murano-tempest-plugin
sahara
sahara-dashboard
sahara-image-elements
sahara-plugin-ambari
sahara-plugin-cdh
sahara-plugin-mapr
sahara-plugin-spark
sahara-plugin-storm
sahara-plugin-vanilla
sahara-tests
senlin
senlinclient
puppet-ec2api
puppet-etcd
puppet-haproxy
puppet-module-data
puppet-murano
puppet-qdr
puppet-rsyslog
puppet-sahara
During the next release we will continue working on retiring inactive packages in order to ensure RDO content quality and security.
Contributors
During the Caracal cycle, we saw the following new RDO contributors:
Marihan Girgis
Balazs Gibizer
Fiorella Yanac
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 47 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and rdo-website repositories:
Ade Lee
Alfredo Moralejo Alonso
Amy Marrich (spotz)
Arx Cruz
Balazs Gibizer
Bernard Cafarelli
Bohdan Dobrelia
Chandan Kumar
Cyril Roelandt
Daniel Pawlik
Douglas Viroel
Emma Foley
Fabricio Aguiar
Fiorella Yanac
Gregory Thiemonge
Grzegorz Grasza
Harald Jensås
Jiří Podivín
Joan Francesc Gilabert
Joel Capitao
Karolina Kula
Lewis Denny
Lon Hohberger
Luigi Toscano
Luis Tomas Bolivar
Lukáš Piwowarski
Maor Blaustein
Marihan Girgis
Marios Andreou
Martin Kopec
Martin Magr
Mathieu Bultel
Michael Johnson
Nate Johnston
Pablo Rodríguez Nava
Priscila Gutierres
Rabi Mishra
Roberto Alfieri
Ronelle Landy
Shreshtha Joshi
Soniya Vyas
Szymon Datko
Takashi Kajinami
Tobias Urdin
Tristan De Cacqueray
Yatin Karel
Zane Bitter
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Dalmatian.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
For those that do not have any hardware or physical resources, there is the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS IRC channels (#centos, #centos-cloud, #centos-devel in Libera.Chat network), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
In this post, we take a look at how to apply custom Nginx configuration directives when you’re using the NGINX Gateway Fabric.
What’s the NGINX Gateway Fabric?
The NGINX Gateway Fabric is an implementation of the Kubernetes Gateway API.
What’s the Gateway API?
The Gateway API is an evolution of the Ingress API; it aims to provide a flexible mechanism for managing north/south network traffic (that is, traffic entering or exiting your Kubernetes cluster), with additional work to support east/west traffic (traffic between pods in your cluster).
What’s this about custom configuration?
I’ve deployed a local development cluster, and I wanted to be able to push images into an image registry hosted on the cluster. This requires (a) running a registry, which is easy, and (b) somehow exposing that registry outside the cluster, which is also easy unless you decide to make it more complex.
In this case, I decided that rather than running an Ingress provider I was going to start familiarizing myself with the Gateway API, so I deployed NGINX Gateway Fabric. My first attempt at pushing an image into the registry looked like this:
Nginx, by default, restricts the maximum size of a request body to 1m, which is to say, 1 megabyte. You can increase (or remove) this limit by setting the client_max_body_size parameter…but how do you do this in the context of a managed deployment like the NGINX Gateway Fabric?
Via the API?
As of this writing, there is no mechanism to apply custom configuration options via the API (although there is ongoing work to provide this, see issue #1258).
What about dropping a config file into conf.d?
My first thought was that I could mount a custom configuration file into /etc/nginx/conf.d, along the lines of:
Right now, the solution is to replace /etc/nginx/nginx.conf. This is a relatively simple operation using kustomize to apply a patch to the deployment manifests.
Grab the original configuration
First, we need to retrieve the originalnginx.conf:
The RDO community is pleased to announce the general availability of the RDO build for OpenStack 2023.2 Bobcat for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Bobcat is the 28th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The release is already available for CentOS Stream 9 on the CentOS mirror network in:
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
New Cinder driver features were added, notably, QoS support for Fujitsu ETERNUS DX driver, replication-enabled consistency groups support for Pure Storage driver, and Active/Active support for NetApp NFS driver.
Glance added support for RBD driver to move images to the trash if they cannot be deleted immediately due to having snapshots.
The Neutron service has enabled the new API policies (RBAC) with system scope and default roles by default.
The Nova legacy quota driver is now deprecated and a nova-manage limits command is provided in order to migrate the orginal limits into Keystone. We plan to change the default quota driver to the unified limits driver in an upcoming release. It is recommended that you begin planning and executing a migration to unified limits as soon as possible.
RDO Bobcat 2023.2 has been built and tested with the recently released Ceph 18.2.0 Reef version (https://docs.ceph.com/en/latest/releases/reef/) which has been published by the CentOS Storage SIG in the official CentOS repositories. *Note:* Follow the instructions in [RDO documentation](https://www.rdoproject.org/install/install-with-ceph/) to install OpenStack and Ceph services in the same host.
During the Bobcat 2023.2 development cycle, the RDO community has implemented automatic dependency detection at run and build time. We expect that these changes will lead to more accurate dependency chains in OpenStack packages and less manual maintenance tasks for community maintainers.
Following upstream retirement, some packages are not present in RDO Bobcat 2023.2 release:
python-networking-odl
python-networking-omnipath
python-networking-vmware-nsx
python-oswin-tests-tempest
python-os-xenapi
python-patrole
python-stackviz
python-vmware-nsxlib
python-vmware-nsx-tests-tempest
Contributors
During the Bobcat cycle, we saw the following new RDO contributors:
Arkady Shtempler
Dariusz Smigiel
Dave Wilde
Fabricio Aguiar
Jakub Skunda
Joan Francesc Gilabert
Maor Blaustein
Mohammad Abunemeh
Szymon Datko
Yadnesh Kulkarni
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 47 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and rdo-website repositories:
Alfredo Moralejo Alonso
Amy Marrich
Ananya Banerjee
Arkady Shtempler
Artom Lifshitz
Arx Cruz
Bhagyashri Shewale
Bohdan Dobrelia
Chandan Kumar
Daniel Pawlik
Dariusz Smigiel
Dave Wilde
Douglas Viroel
Enrique Vallespi Gil
Fabricio Aguiar
Giulio Fidente
Goutham Pacha Ravi
Gregory Thiemonge
Grzegorz Grasza
Ihar Hrachyshka
Jakub Skunda
Jiří Podivín
Jiří Stránský
Joan Francesc Gilabert
Joel Capitao
Karolina Kula
Karthik Sundaravel
Luca Miccini
Lucas Alvares Gomes
Luigi Toscano
Luis Tomas Bolivar
Maor Blaustein
Marios Andreou
Mathieu Bultel
Matthias Runge
Mohammad Abunemeh
Rodolfo Alonso Hernandez
Ronelle Landy
Sandeep Yadav
Slawomir Kaplonski
Soniya29 vyas
Szymon Datko
Takashi Kajinami
Tobias Urdin
Tom Weininger
Yadnesh Kulkarni
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Caracal.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS IRC channels (#centos, #centos-cloud, #centos-devel in Libera.Chat network), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
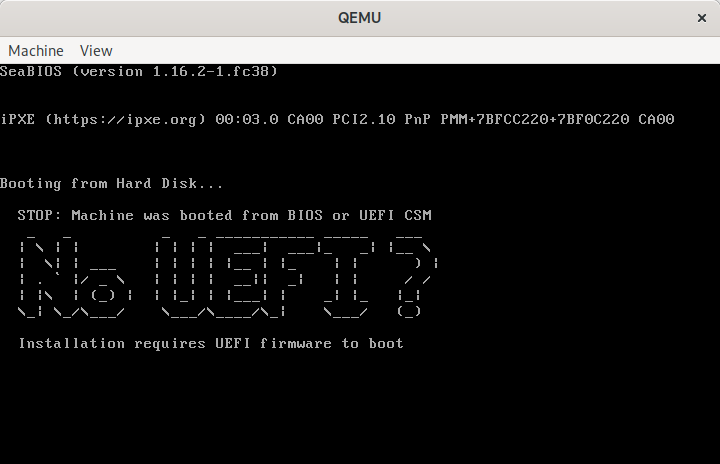
The x86 platform has been ever so slowly moving towards a world where EFI is used to boot everything, with legacy BIOS put out to pasture. Virtual machines in general have been somewhat behind the cutting edge in this respect though. This has mostly been due to the virtualization and cloud platforms being somewhat slow in enabling use of EFI at all, let alone making it the default. In a great many cases the platforms still default to using BIOS unless explicitly asked to use EFI. With this in mind most the mainstream distros tend to provide general purpose disk images built such that they can boot under either BIOS or EFI, thus adapting to whatever environment the user deploys them in.
In recent times there is greater interest in the use of TPM sealing and SecureBoot for protecting guest secrets (eg LUKS passphrases), the introduction of UKIs as the means to extend the SecureBoot signature to close initrd/cmdline hole, and the advent of confidential virtualization technology. These all combine to increase the liklihood that a virtual machine image will exclusively target EFI, fully discontinuing support for legacy BIOS.
This presents a bit of a usability trapdoor for people deploying images though, as it has been taken for granted that BIOS boot always works. If one takes an EFI only disk image and attempts to boot it via legacy BIOS, the user is likely to get an entirely blank graphical display and/or serial console, with no obvious hint that EFI is required. Even if the requirement for EFI is documented, it is inevitable that users will make mistakes.
This is a simple command line tool that, when pointed to a disk image, will inject a MBR sector that prints out a message to the user on the primary VGA display and serial port informing them that UEFI is required, then puts the CPUs in a ‘hlt‘ loop.
The usage is as follows, with a guest serial port connected to the local terminal:
The byebyebios python tool takes this bootstub.bin, appends the text message and NUL terminator, padding to fill 446 bytes, then adds a dummy partition table and boot signature to fill the whole 512 sector.
With the boot stub binary at 21 bytes in size, this leaves 424 bytes available for the message to display to the user, which is ample for the purpose.
In conclusion, if you need to ship an EFI only virtual machine image, do your users a favour and use byebyebios to add a dummy MBR to tell them that the image is EFI only when they inevitably make a mistake and run it under legacy BIOS.
I recently found myself wanting to perform a few transformations on a large OpenAPI schema. In particular, I wanted to take the schema available from the /openapi/v2 endpoint of a Kubernetes server and minimize it by (a) extracting a subset of the definitions and (b) removing all the description attributes.
The first task is relatively easy, since everything of interest exists at the same level in the schema. If I want one or more specific definitions, I can simply ask for those by key. For example, if I want the definition of a DeploymentConfig object, I can run:
So simple! And so wrong! Because while that does extract the required definition, that definition is not self-contained: it refers to other definitions via $ref pointers. The real solution would require code that parses the schema, resolves all the $ref pointers, and spits out a fully resolved schema. Fortunately, in this case we can get what we need by asking for schemas matching a few specific prefixes. Using jq, we can match keys against a prefix by:
Using the to_entries filter to transform a dictionary into a list of {"key": ..., "value": ...} dictionaries, and then
Using select with the startswith function to match specific keys, and finally
Reconstructing the data with from_entries
Which looks like:
jq '[.definitions|to_entries[]|select(
(.key|startswith("com.github.openshift.api.apps.v1.Deployment")) or
(.key|startswith("io.k8s.apimachinery")) or
(.key|startswith("io.k8s.api.core"))
)]|from_entries' < openapi.json
That works, but results in almost 500KB of output, which seems excessive. We could further reduce the size of the document by removing all the description elements, but here is where things get tricky: description attributes can occur throughout the schema hierarchy, so we can’t use a simple path (...|del(.value.description) to remove them.
A simple solution is to use sed:
jq ... | sed '/"description"/d'
While normally I would never use sed for processing JSON, that actually works in this case: because we’re first running the JSON document through jq, we can be confident about the formatting of the document being passed through sed, and anywhere the string "description" is contained in the value of an attribute the quotes will be escaped so we would see \"description\".
We could stop here and things would be just fine…but I was looking for a way to perform the same operation in a structured fashion. What I really wanted was an equivalent to xpath’s // operator (e.g., the path //description would find all <description> elements in a document, regardless of how deeply they were nested), but no such equivalent exists in jq. Then I came across the tostream filter, which is really neat: it transforms a JSON document into a sequence of [path, leaf-value] nodes (or [path] to indicate the end of an array or object).
You can see how each attribute is represented by a tuple. For example, for .count.local, the first element of the tuple is ["count", "local"], representing that path to the value in the document, and the second element is the value itself (1). The “end” of an object is indicated by a 1-tuple ([path]), such as [["count"]] at the end of this example.
If we convert the OpenAPI schema to a stream, we’ll end up with nodes for the description attributes that look like this:
[
[
"com.github.openshift.api.apps.v1.DeploymentCause",
"properties",
"imageTrigger",
"description"
],
"ImageTrigger contains the image trigger details, if this trigger was fired based on an image change"
]
To match those, we need to look for nodes for which the last element of the first item is description. That is:
...|tostream|select(.[0][-1]=="description"))
Of course, we don’t want to select those nodes; we want to delete them:
And lastly, we need to feed the result back to the fromstream function to reconstruct the document. Putting all of that together – and populating some required top-level keys so that we end up with a valid OpenAPI schema – looks like this:
jq '
fromstream(
{
"swagger": .swagger,
"definitions": [
.definitions|to_entries[]|select(
(.key|startswith("com.github.openshift.api.apps.v1.Deployment")) or
(.key|startswith("io.k8s.apimachinery")) or
(.key|startswith("io.k8s.api.core"))
)]|from_entries
}|tostream|del(select(.[0][-1]=="description"))|select(. != null)
)
'
In my environment, this reduces the size of the resulting file from about 500KB to around 175KB.
A software fixture “sets up a system for the software testing process by initializing it, thereby satisfying any preconditions the system may have”. They allow us to perform setup and teardown tasks, provide state or set up services required for our tests, and perform other initialization tasks. In this article, we’re going to explore how to use fixtures in Pytest to create and tear down containers as part of a test run.
Pytest Fixtures
Pytest fixtures are created through the use of the fixture decorator. A fixture is accessed by including a function parameter with the fixture name in our test functions. For example, if we define an example fixture:
And it will receive the string “hello world” as the value of the example parameter.
There are a number of built-in fixtures available; for example, the tmp_path fixture provides access to a temporary directory that is unique to each test function. The following function would create a file named myfile in the temporary directory; the file (in fact, the entire directory) will be removed automatically when the function completes:
deftest_something(tmp_path):
with (tmp_path /"myfile").open() as fd:
fd.write('this is a test')
A fixture can declare a scope; the default is the function scope – a new value will be generated for each function. A fixture can also be declared with a scope of class, module, package, or session (where “session” means, effectively, a distinct run of pytest).
Fixtures can be located in the same files as your tests, or they can be placed in a conftest.py file where they can be shared between multiple sets of tests.
Communicating with Docker
In order to manage containers as part of the test process we’re going to need to interact with Docker. While we could call out to the docker CLI from our tests, a more graceful solution is to use the Docker client for Python. That means we’ll need a Docker client instance, so we start with a very simple fixture:
import docker
@pytest.fixture(scope="session")
defdocker_client():
"""Return a Docker client"""return docker.from_env()
This returns a Docker client initialized using values from the environment (in other words, it behaves very much like the docker cli).
I’ve made this a session scoped fixture (which means we create one Docker client object at per pytest run, and every test using this fixture will receive the same object). This makes sense in general because a Docker client is stateless; there isn’t any data we need to reset between tests.
Starting a container, version 1
For the purposes of this article, let’s assume we want to spin up a MariaDB server in a container. From the command line we might run something like this:
This works, but it’s not great. In particular, the container we create will hang around until we remove it manually, since we didn’t arrange to remove the container on completion. Since this is a function scoped fixture, we would end up with one container per test (potentially leading to hundreds of containers running for a large test suite).
Starting a container, version 2
Let’s take care of the biggest problem with the previous implementation and ensure that our containers get cleaned up. We can add cleanup code to a fixture by using a yield fixture; instead of return-ing a value, we yield a value, and any cleanup code after the yield statement runs when the fixture is no longer in scope.
That’s better, but we’re not out of the woods yet. How would we use this fixture in a test? Maybe we would try something like this:
import mysql.connector
def test_simple_select(mariadb_container):
# get the address of the mariadb container
mariadb_container.reload()
addr = mariadb_container.attrs["NetworkSettings"]["Networks"]["bridge"]["IPAddress"]
# create a connection objects
conn = mysql.connector.connect(
host=addr, user="root", password="secret", database="testdb"
)
# try a simple select statement
curs = conn.cursor()
curs.execute("select 1")
res = curs.fetchone()
assert res[0] == 1
First of all, that’s not a great test; there’s too much setup happening in the test that we would have to repeat before every additional test. And more importantly, if you were to try to run that test it would probably fail with:
E mysql.connector.errors.InterfaceError: 2003: Can't connect to MySQL
server on '172.17.0.2:3306' (111 Connection refused)
The problem is that when we start the MariaDB container, MariaDB isn’t ready to handle connections immediately. It takes a couple of seconds after starting the container before the server is ready. Because we haven’t accounted for that in our test, there’s nothing listening when we try to connect.
A step back and a moving forward
To resolve the issues in the previous example, let’s first take a step back. For our test, we don’t actually want a container; what we want is the ability to perform SQL queries in our test with a minimal amount of boilerplate. Ideally, our test would look more like this:
deftest_simple_select(mariadb_cursor):
curs.execute('select 1')
res = curs.fetchone()
assert res[0] ==1
How do we get there?
Working backwards, we would need a mariadb_cursor fixture:
@pytest.fixturedefmariadb_cursor(...):
...
But to get a database cursor, we need a database connection:
@pytest.fixturedefmariadb_connection(...):
...
And to create a database connection, we need to know the address of the database server:
@pytest.fixturedefmariadb_host(...):
...
Let’s start filling in all those ellipses.
What would the mariadb_host fixture look like? We saw in our earlier test code how to get the address of a Docker container. Much like the situation with the database server, we want to account for the fact that it might take a nonzero amount of time for the container network setup to complete, so we can use a simple loop in which we check for the address and return it if it’s available, otherwise sleep a bit and try again:
The logic here is very similar; we keep attempting to establish a connection until we’re successful, at which point we return the connection object.
Now that we have a fixture that gives us a functioning database connection, we can use that to acquire a cursor:
from contextlib import closing
@pytest.fixturedefmariadb_cursor(mariadb_connection):
with closing(mariadb_connection.cursor()) as cursor:
yield cursor
The closing method from the contextlib module returns a context manager that calls the close method on the given object when leaving the with context; this ensures that the cursor is closed when we’re done with it. We could have accomplished the same thing by writing this instead:
In order to keep this post to a reasonable size, we haven’t bothered to create an actual application, which means we haven’t had to worry about things like initializing the database schema. In reality, we would probably handle that in a new or existing fixture.
Replaced hardcoded values
While our fixture does the job, we’re using a number of hardcoded values (for the username, the database name, the password, etc). This isn’t inherently bad for a test environment, but it can sometimes mask errors in our code (for example, if we pick values that match default values in our code, we might miss errors that crop up when using non-default values).
We can replace fixed strings with fixtures that produce random values (or values with a random component, if we want something a little more human readable). In the following example, we have a random_string fixture that produces an 8 character random string, and then we use that to produce a password and a database name:
The fixtures we’ve developed in this post have all been function scoped, which means that we’re creating and tearing down a container for every single function. This will substantially increase the runtime of our tests. We may want to consider using session scoped fixtures instead; this would bring up a container and it use it for all our tests, only cleaning it up at the end of the test run.
The advantage here is that the impact on the test run time is minimal. The disadvantage is that we have to be very careful about the interaction between tests, since we would no longer be starting each test with a clean version of the database.
Keep in mind that in Pytest, a fixture can only reference other fixtures that come from the same or “broader” scope (so, a function scoped fixture can use a session scoped fixture, but the opposite is not true). In particular, that means if we were to make our mariadb_container fixture session-scoped, we would need to make the same change to its dependencies (mariadb_dbname, mariadb_dbpass, etc).
You can find a version of conftest.py with these changes here.
The RDO community is pleased to announce the general availability of the RDO build for OpenStack 2023.1 Antelope for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Antelope is the 27th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The release is already available for CentOS Stream 9 on the CentOS mirror network in:
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
The continuation of SRBAC and FIPS to make OpenStack a more secure platform across various services, along with additional support in images.
Additional drivers and features for Block Storage to support more technologies from vendors such as Dell, Hitachi and NetApp, among others.
DNS Zones that can now be shared with other tenants (projects) allowing them to create and manage recordsets within the Zone.
Networking port forwarding was added to the dashboard for Floating IPs.
Additional networking features to support OVN.
Compute now allows PCI devices to be scheduled via the Placement API and power consumption can be managed for dedicated CPUs.
Load balancing now allows users to enable cpu-pinning.
Community testing of compatibility between non-adjacent upstream versions.
OpenStack Antelope is the first release marked as Skip Level Upgrade Release Process or SLURP. According to this model (https://governance.openstack.org/tc/resolutions/20220210-release-cadence-adjustment.html) this means that upgrades will be supported between these (SLURP) releases, in addition to between adjacent major releases.
TripleO removal in the RDO Antelope release: During the Antelope cycle, The TripleO team communicated the decision of abandoning the development of the project and deprecating the master branches. According to that upstream decision, TripleO packages have been removed from the RDO distribution and will not be included in the Antelope release.
Contributors During the Zed cycle, we saw the following new RDO contributors:
Adrian Fusco Arnejo
Bhagyashri Shewale
Eduardo Olivares
Elvira Garcia Ruiz
Enrique Vallespí
Jason Paroly
Juan Badia Payno
Karthik Sundaravel
Roberto Alfieri
Tom Weininger
Welcome to all of you and Thank You So Much for participating! But we wouldn’t want to overlook anyone.
A super massive Thank You to all 52 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and rdo-website repositories:
Adrian Fusco Arnejo
Alan Pevec
Alfredo Moralejo Alonso
Amol Kahat
Amy Marrich
Ananya Banerjee
Artom Lifshitz
Arx Cruz
Bhagyashri Shewale
Cédric Jeanneret
Chandan Kumar
Daniel Pawlik
Dariusz Smigiel
Dmitry Tantsur
Douglas Viroel
Eduardo Olivares
Elvira Garcia Ruiz
Emma Foley
Eric Harney
Enrique Vallespí
Fabien Boucher
Harald Jensas
Jakob Meng
Jason Paroly
Jesse Pretorius
Jiří Podivín
Joel Capitao
Juan Badia Payno
Julia Kreger
Karolina Kula
Karthik Sundaravel
Leif Madsen
Luigi Toscano
Luis Tomas Bolivar
Marios Andreou
Martin Kopec
Matthias Runge
Matthieu Huin
Nicolas Hicher
Pooja Jadhav
Rabi Mishra
Riccardo Pittau
Roberto Alfieri
Ronelle Landy
Sandeep Yadav
Sean Mooney
Slawomir Kaplonski
Steve Baker
Takashi Kajinami
Tobias Urdin
Tom Weininger
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Bobcat.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS IRC channels (#centos, #centos-cloud, and #centos-devel in Libera.Chat network), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation. Join us in #rdo on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
<p>Last week, Oskar Stenberg asked on <a href="https://unix.stackexchange.com/q/735931/4989">Unix & Linux</a> if it were possible to configure connectivity between two networks, both using the same address range, without involving network namespaces. That is, given this high level view of the network…</p>
<p><a href="https://excalidraw.com/#json=uuXRRZ2ybaAXiUvbQVkNO,krx3lsbf12c-tDhuWtRjbg"><img alt="two networks with the same address range connected by a host named “middleman”" src="https://blog.oddbit.com/post/2023-02-19-vrf-and-nat/the-problem.svg"></a></p>
<p>…can we set things up so that hosts on the “inner” network can communicate with hosts on the “outer” network using the range <code>192.168.3.0/24</code>, and similarly for communication in the other direction?</p>
<h2 id="setting-up-a-lab">Setting up a lab</h2>
<p>When investigating this sort of networking question, I find it easiest to reproduce the topology in a virtual environment so that it’s easy to test things out. I generally use <a href="https://mininet.org">Mininet</a> for this, which provides a simple Python API for creating virtual nodes and switches and creating links between them.</p>
<p>I created the following network topology for this test:</p>
<figure class="center" >
<img src="topology-1.svg" alt="virtual network topology diagram" />
</figure>
<p>In the rest of this post, I’ll be referring to these hostnames.</p>
<p>See the bottom of this post for a link to the repository that contains the complete test environment.</p>
<h2 id="vrf-in-theory">VRF in theory</h2>
<p>VRF stands for “Virtual Routing and Forwarding”. From the <a href="https://en.wikipedia.org/wiki/Virtual_routing_and_forwarding">Wikipedia article on the topic</a>:</p>
<blockquote>
<p>In IP-based computer networks, virtual routing and forwarding (VRF) is a technology that allows multiple instances of a routing table to co-exist within the same router at the same time. One or more logical or physical interfaces may have a VRF and these VRFs do not share routes therefore the packets are only forwarded between interfaces on the same VRF. VRFs are the TCP/IP layer 3 equivalent of a VLAN. Because the routing instances are independent, the same or overlapping IP addresses can be used without conflicting with each other. Network functionality is improved because network paths can be segmented without requiring multiple routers.<a href="https://blog.oddbit.com/post/2023-02-19-vrf-and-nat/the-problem.svg">1</a></p>
</blockquote>
<p>In Linux, VRF support is implemented as a <a href="https://docs.kernel.org/networking/vrf.html">special type of network device</a>. A VRF device sets up an isolated routing domain; network traffic on devices associated with a VRF will use the routing table associated with that VRF, rather than the main routing table, which permits us to connect multiple networks with overlapping address ranges.</p>
<p>We can create new VRF devices with the <code>ip link add</code> command:</p>
<pre tabindex="0"><code>ip link add vrf-inner type vrf table 100
</code></pre><p>Running the above command results in the following changes:</p>
<ul>
<li>
<p>It creates a new network device named <code>vrf-inner</code></p>
</li>
<li>
<p>It adds a new route policy rule (if it doesn’t already exist) that looks like:</p>
<pre tabindex="0"><code>1000: from all lookup [l3mdev-table]
</code></pre><p>This causes route lookups to use the appropriate route table for interfaces associated with a VRF.</p>
</li>
</ul>
<p>After creating a VRF device, we can add interfaces to it like this:</p>
<pre tabindex="0"><code>ip link set eth0 master vrf-inner
</code></pre><p>This associates the given interface with the VRF device, and it moves all routes associated with the interface out of the <code>local</code> and <code>main</code> routing tables and into the VRF-specific routing table.</p>
<p>You can see a list of vrf devices by running <code>ip vrf show</code>:</p>
<pre tabindex="0"><code># ip vrf show
Name Table
-----------------------
vrf-inner 100
</code></pre><p>You can see a list of devices associated with a particular VRF with the <code>ip link</code> command:</p>
<pre tabindex="0"><code># ip -brief link show master vrf-inner
eth0@if448 UP 72:87:af:d3:b5:f9 <BROADCAST,MULTICAST,UP,LOWER_UP>
</code></pre><h2 id="vrf-in-practice">VRF in practice</h2>
<p>We’re going to create two VRF devices on the <code>middleman</code> host; one associated with the “inner” network and one associated with the “outer” network. In our virtual network topology, the <code>middleman</code> host has two network interfaces:</p>
<ul>
<li><code>middleman-eth0</code> is connected to the “inner” network</li>
<li><code>middleman-eth1</code> is connected to the “outer” network</li>
</ul>
<p>Both devices have the same address (<code>192.168.2.1</code>):</p>
<pre tabindex="0"><code># ip addr show
2: middleman-eth0@if426: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vrf-inner state UP group default qlen 1000
link/ether 32:9e:01:2e:78:2f brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.2.1/24 brd 192.168.2.255 scope global middleman-eth0
valid_lft forever preferred_lft forever
root@mininet-vm:~/unix-735931# ip addr show middleman-eth1
3: middleman-eth1@if427: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vrf-outer state UP group default qlen 1000
link/ether 12:be:9a:09:33:93 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.2.1/24 brd 192.168.2.255 scope global middleman-eth1
valid_lft forever preferred_lft forever
</code></pre><p>And the main routing table looks like this:</p>
<pre tabindex="0"><code># ip route show
192.168.2.0/24 dev middleman-eth1 proto kernel scope link src 192.168.2.1
192.168.2.0/24 dev middleman-eth0 proto kernel scope link src 192.168.2.1
</code></pre><p>If you’re at all familiar with Linux network configuration, that probably looks weird. Right now this isn’t a particularly functional network configuration, but we can fix that!</p>
<p>To create our two VRF devices, we run the following commands:</p>
<pre tabindex="0"><code>ip link add vrf-inner type vrf table 100
ip link add vrf-outer type vrf table 200
ip link set vrf-inner up
ip link set vrf-outer up
</code></pre><p>This associates <code>vrf-inner</code> with route table 100, and <code>vrf-outer</code> with route table 200. At this point, tables 100 and 200 are empty:</p>
<pre tabindex="0"><code># ip route show table 100
Error: ipv4: FIB table does not exist.
Dump terminated
# ip route show table 200
Error: ipv4: FIB table does not exist.
Dump terminated
</code></pre><p>Next, we add our interfaces to the appropriate VRF devices:</p>
<pre tabindex="0"><code>ip link set middleman-eth0 master vrf-inner
ip link set middleman-eth1 master vrf-outer
</code></pre><p>After running these commands, there are no routes left in the main routing table:</p>
<pre tabindex="0"><code># ip route show
<no output>
</code></pre><p>And the routes associated with our two physical interfaces are now contained by the appropriate VRF routing tables. Here’s table 100:</p>
<pre tabindex="0"><code>root@mininet-vm:~/unix-735931# ip route show table 100
broadcast 192.168.2.0 dev middleman-eth0 proto kernel scope link src 192.168.2.1
192.168.2.0/24 dev middleman-eth0 proto kernel scope link src 192.168.2.1
local 192.168.2.1 dev middleman-eth0 proto kernel scope host src 192.168.2.1
broadcast 192.168.2.255 dev middleman-eth0 proto kernel scope link src 192.168.2.1
</code></pre><p>And table 200:</p>
<pre tabindex="0"><code>root@mininet-vm:~/unix-735931# ip route show table 200
broadcast 192.168.2.0 dev middleman-eth1 proto kernel scope link src 192.168.2.1
192.168.2.0/24 dev middleman-eth1 proto kernel scope link src 192.168.2.1
local 192.168.2.1 dev middleman-eth1 proto kernel scope host src 192.168.2.1
broadcast 192.168.2.255 dev middleman-eth1 proto kernel scope link src 192.168.2.1
</code></pre><p>This configuration effectively gives us two isolated networks:</p>
<figure class="center" >
<img src="topology-2.svg" alt="virtual network topology diagram" />
</figure>
<p>We can verify that nodes in the “inner” and “outer” networks are now able to communicate with <code>middleman</code>. We can reach <code>middleman</code> from <code>innernode0</code>; in this case, we’re communicating with interface <code>middleman-eth0</code>:</p>
<pre tabindex="0"><code>innernode0# ping -c1 192.168.2.1
PING 192.168.2.1 (192.168.2.1) 56(84) bytes of data.
64 bytes from 192.168.2.1: icmp_seq=1 ttl=64 time=0.126 ms
--- 192.168.2.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.126/0.126/0.126/0.000 ms
</code></pre><p>Similarly, we can reach <code>middleman</code> from <code>outernode</code>, but in this case we’re communicating with interface <code>middleman-eth1</code>:</p>
<pre tabindex="0"><code>outernode0# ping -c1 192.168.2.1
PING 192.168.2.1 (192.168.2.1) 56(84) bytes of data.
64 bytes from 192.168.2.1: icmp_seq=1 ttl=64 time=1.02 ms
--- 192.168.2.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 1.020/1.020/1.020/0.000 ms
</code></pre><h2 id="configure-routing-on-the-nodes">Configure routing on the nodes</h2>
<p>Our goal is to let nodes on one side of the network to use the address range <code>192.168.3.0/24</code> to refer to nodes on the other side of the network. Right now, if we were to try to access <code>192.168.3.10</code> from <code>innernode0</code>, the attempt would fail with:</p>
<pre tabindex="0"><code>innernode0# ping 192.168.3.10
ping: connect: Network is unreachable
</code></pre><p>The “network is unreachable” message means that <code>innernode0</code> has no idea where to send that request. That’s because at the moment, the routing table on all the nodes look like:</p>
<pre tabindex="0"><code>innernode0# ip route
192.168.2.0/24 dev outernode0-eth0 proto kernel scope link src 192.168.2.10
</code></pre><p>There is neither a default gateway nor a network-specific route appropriate for <code>192.168.3.0/24</code> addresses. Let’s add a network route that will route that address range through <code>middleman</code>:</p>
<pre tabindex="0"><code>innernode0# ip route add 192.168.3.0/24 via 192.168.2.1
innernode0# ip route
192.168.2.0/24 dev innernode0-eth0 proto kernel scope link src 192.168.2.10
192.168.3.0/24 via 192.168.2.1 dev innernode0-eth0
</code></pre><p>This same change needs to be made on all the <code>innernode*</code> and <code>outernode*</code> nodes.</p>
<p>With the route in place, attempts to reach <code>192.168.3.10</code> from <code>innernode0</code> will still fail, but now they’re getting rejected by <code>middleman</code> because <em>it</em> doesn’t have any appropriate routes:</p>
<pre tabindex="0"><code>innernode0# ping -c1 192.168.3.10
PING 192.168.3.10 (192.168.3.10) 56(84) bytes of data.
From 192.168.2.1 icmp_seq=1 Destination Net Unreachable
--- 192.168.3.10 ping statistics ---
1 packets transmitted, 0 received, +1 errors, 100% packet loss, time 0ms
</code></pre><p>We need to tell <code>middleman</code> what to do with these packets.</p>
<h2 id="configure-routing-and-nat-on-middleman">Configure routing and NAT on middleman</h2>
<p>In order to achieve our desired connectivity, we need to:</p>
<ol>
<li>Map the <code>192.168.3.0/24</code> destination address to the equivalent <code>192.168.2.0/24</code> address <em>before</em> the kernel makes a routing decision.</li>
<li>Map the <code>192.168.2.0/24</code> source address to the equivalent <code>192.168.3.0/24</code> address <em>after</em> the kernel makes a routing decision (so that replies will go back to “other” side).</li>
<li>Ensure that the kernel uses the routing table for the <em>target</em> network when making routing decisions for these connections.</li>
</ol>
<p>We can achieve (1) and (2) using the netfilter <a href="https://www.netfilter.org/documentation/HOWTO/netfilter-extensions-HOWTO-4.html#ss4.4"><code>NETMAP</code></a> extension by adding the following two rules:</p>
<pre tabindex="0"><code>iptables -t nat -A PREROUTING -d 192.168.3.0/24 -j NETMAP --to 192.168.2.0/24
iptables -t nat -A POSTROUTING -s 192.168.2.0/24 -j NETMAP --to 192.168.3.0/24
</code></pre><p>For incoming traffic destined for the 192.168.3.0/24 network, this maps the destination address to the matching <code>192.168.2.0/24</code> address. For outgoing traffic with a source address on the <code>192.168.2.0/24</code> network, this maps the source to the equivalent <code>192.168.3.0/24</code> network (so that the recipient see the traffic as coming from “the other side”).</p>
<p>(For those of you wondering, “can we do this using <code>nftables</code> instead?”, as of this writing <a href="https://wiki.nftables.org/wiki-nftables/index.php/Supported_features_compared_to_xtables#NETMAP"><code>nftables</code> does not appear to have <code>NETMAP</code> support</a>, so we have to use <code>iptables</code> for this step.)</p>
<p>With this change in place, re-trying that <code>ping</code> command on <code>innernode0</code> will apparently succeed:</p>
<pre tabindex="0"><code>innernode0 ping -c1 192.168.3.10
PING 192.168.3.10 (192.168.3.10) 56(84) bytes of data.
64 bytes from 192.168.3.10: icmp_seq=1 ttl=63 time=0.063 ms
--- 192.168.3.10 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.063/0.063/0.063/0.000 ms
</code></pre><p>However, running <code>tcpdump</code> on <code>middleman</code> will show us that we haven’t yet achieved our goal:</p>
<pre tabindex="0"><code>12:59:52.899054 middleman-eth0 In IP 192.168.2.10 > 192.168.3.10: ICMP echo request, id 16520, seq 1, length 64
12:59:52.899077 middleman-eth0 Out IP 192.168.3.10 > 192.168.2.10: ICMP echo request, id 16520, seq 1, length 64
12:59:52.899127 middleman-eth0 In IP 192.168.2.10 > 192.168.3.10: ICMP echo reply, id 16520, seq 1, length 64
12:59:52.899130 middleman-eth0 Out IP 192.168.3.10 > 192.168.2.10: ICMP echo reply, id 16520, seq 1, length 64
</code></pre><p>You can see that our packet is coming on on <code>middleman-eth0</code>…and going right back out the same interface. We have thus far achieved a very complicated loopback interface.</p>
<p>The missing piece is some logic to have the kernel use the routing table for the “other side” when making routing decisions for these packets. We’re going to do that by:</p>
<ol>
<li>Tagging packets with a mark that indicates the interface on which they were recieved</li>
<li>Using this mark to select an appropriate routing table</li>
</ol>
<p>We add the packet mark by adding these rules to the <code>MANGLE</code> table <code>PREROUTING</code> chain:</p>
<pre tabindex="0"><code>iptables -t mangle -A PREROUTING -i middleman-eth0 -d 192.168.3.0/24 -j MARK --set-mark 100
iptables -t mangle -A PREROUTING -i middleman-eth1 -d 192.168.3.0/24 -j MARK --set-mark 200
</code></pre><p>And we utilize that mark in route lookups by adding the following two route policy rules:</p>
<pre tabindex="0"><code>ip rule add prio 100 fwmark 100 lookup 200
ip rule add prio 200 fwmark 200 lookup 100
</code></pre><p>It is critical that these rules come before (aka “have a higher priority than”, aka “have a lower number than”) the <code>l3mdev</code> rule added when we created the VRF devices.</p>
<h2 id="validation-does-it-actually-work">Validation: Does it actually work?</h2>
<p>With that last set of changes in place, if we repeat the <code>ping</code> test from <code>innernode0</code> to <code>outernode0</code> and run <code>tcpdump</code> on <code>middleman</code>, we see:</p>
<pre tabindex="0"><code>13:05:27.667793 middleman-eth0 In IP 192.168.2.10 > 192.168.3.10: ICMP echo request, id 16556, seq 1, length 64
13:05:27.667816 middleman-eth1 Out IP 192.168.3.10 > 192.168.2.10: ICMP echo request, id 16556, seq 1, length 64
13:05:27.667863 middleman-eth1 In IP 192.168.2.10 > 192.168.3.10: ICMP echo reply, id 16556, seq 1, length 64
13:05:27.667868 middleman-eth0 Out IP 192.168.3.10 > 192.168.2.10: ICMP echo reply, id 16556, seq 1, length 64
</code></pre><p>Now we finally see the desired behavior: the request from <code>innernode0</code> comes in on <code>eth0</code>, goes out on <code>eth1</code> with the addresses appropriately mapped and gets delivered to <code>outernode0</code>. The reply from <code>outernode0</code> goes through the process in reverse, and arrives back at <code>innernode0</code>.</p>
<h2 id="connection-tracking-or-one-more-thing">Connection tracking (or, “One more thing…”)</h2>
<p>There is a subtle problem with the configuration we’ve implemented so far: the Linux connection tracking mechanism ("<a href="https://arthurchiao.art/blog/conntrack-design-and-implementation/">conntrack</a>") by default identifies a connection by the 4-tuple <code>(source_address, source_port, destination_address, destination_port)</code>. To understand why this is a problem, assume that we’re running a web server on port 80 on all the “inner” and “outer” nodes.</p>
<p>To connect from <code>innernode0</code> to <code>outernode0</code>, we could use the following command. We’re using the <code>--local-port</code> option here because we want to control the source port of our connections:</p>
<pre tabindex="0"><code>innernode0# curl --local-port 4000 192.168.3.10
</code></pre><p>To connect from <code>outernode0</code> to <code>innernode0</code>, we would use the same command:</p>
<pre tabindex="0"><code>outernode0# curl --local-port 4000 192.168.3.10
</code></pre><p>If we look at the connection tracking table on <code>middleman</code>, we will see a single connection:</p>
<pre tabindex="0"><code>middleman# conntrack -L
tcp 6 115 TIME_WAIT src=192.168.2.10 dst=192.168.3.10 sport=4000 dport=80 src=192.168.2.10 dst=192.168.3.10 sport=80 dport=4000 [ASSURED] mark=0 use=1
</code></pre><p>This happens because the 4-tuple for our two connections is identical. Conflating connections like this can cause traffic to stop flowing if both connections are active at the same time.</p>
<p>We need to provide the connection track subsystem with some additional information to uniquely identify these connections. We can do this by using the netfilter <code>CT</code> module to assign each connection to a unique conntrack origination “zone”:</p>
<pre tabindex="0"><code>iptables -t raw -A PREROUTING -s 192.168.2.0/24 -i middleman-eth0 -j CT --zone-orig 100
iptables -t raw -A PREROUTING -s 192.168.2.0/24 -i middleman-eth1 -j CT --zone-orig 200
</code></pre><p>What is a “zone”? From <a href="https://lore.kernel.org/all/4B9158F5.5040205@parallels.com/T/">the patch adding this feature</a>:</p>
<blockquote>
<p>A zone is simply a numerical identifier associated with a network
device that is incorporated into the various hashes and used to
distinguish entries in addition to the connection tuples.</p>
</blockquote>
<p>With these rules in place, if we repeat the test with <code>curl</code> we will see two distinct connections:</p>
<pre tabindex="0"><code>middleman# conntrack -L
tcp 6 117 TIME_WAIT src=192.168.2.10 dst=192.168.3.10 sport=4000 dport=80 zone-orig=100 src=192.168.2.10 dst=192.168.3.10 sport=80 dport=26148 [ASSURED] mark=0 use=1
tcp 6 115 TIME_WAIT src=192.168.2.10 dst=192.168.3.10 sport=4000 dport=80 zone-orig=200 src=192.168.2.10 dst=192.168.3.10 sport=80 dport=4000 [ASSURED] mark=0 use=1
</code></pre><h2 id="repository-and-demo">Repository and demo</h2>
<p>You can find a complete test environment in <a href="https://github.com/larsks/unix-example-735931-1-1-nat">this repository</a>; that includes the mininet topology I mentioned at the beginning of this post as well as shell scripts to implement all the address, route, and netfilter configurations.</p>
<p>And here’s a video that runs through the steps described in this post:</p>
<div style="position: relative; padding-bottom: 56.25%; height: 0; overflow: hidden;">
<iframe allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen="allowfullscreen" loading="eager" referrerpolicy="strict-origin-when-cross-origin" src="https://www.youtube.com/embed/Kws98JNKcxE?autoplay=0&controls=1&end=0&loop=0&mute=0&start=0" style="position: absolute; top: 0; left: 0; width: 100%; height: 100%; border:0;" title="YouTube video"
></iframe>
</div>
I was recently working with someone else’s C source and I wanted to add some basic error checking without mucking up the code with a bunch of if statements and calls to perror. I ended up implementing a simple must function that checks the return value of an expression, and exits with an error if the return value is less than 0. You use it like this:
must(fd =open("textfile.txt", O_RDONLY));
Or:
must(close(fd));
In the event that an expression returns an error, the code will exit with a message that shows the file, line, and function in which the error occurred, along with the actual text of the called function and the output of perror:
example.c:24 in main: fd = open("does-not-exist.xt", O_RDONLY): [2]: No such file or directory
To be clear, this is only useful when you’re using functions that conform to standard Unix error reporting conventions, and if you’re happy with “exit with an error message” as the failure handling mechanism.
Implementation
The implementation starts with a macro defined in must.h:
The __FILE__, __LINE__, and __func__ symbols are standard predefined symbols provided by gcc; they are documented here. The expression #x is using the stringify operator to convert the macro argument into a string.
The above macro transforms a call to must() into a call to the _must() function, which is defined in must.c:
In this function we check the value of err (which will be the return value of the expression passed as the argument to the must() macro), and if it evaluates to a number less than 0, we use snprintf() to generate a string that we can pass to perror(), and finally call perror() which will print our information string, a colon, and then the error message corresponding to the value of errno.
Example
You can see must() used in practice in the following example program:
#include "must.h"
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
int main() {
int fd;
char buf[1024];
printf("opening a file that does exist\n");
must(fd = open("file-that-exists.txt", O_RDONLY));
while (1) {
int nb;
must(nb = read(fd, buf, sizeof(buf)));
if (!nb)
break;
must(write(STDOUT_FILENO, buf, nb));
}
must(close(fd));
printf("opening a file that doesn't exist\n");
must(fd = open("file-that-does-not-exist.xt", O_RDONLY));
return 0;
}
Provided the file-that-exists.txt (a) exists and (b) contains the text Hello, world., and that file-that-does-not-exist.txt does not, in fact, exist, running the above code will produce the following output:
opening a file that does exist
Hello, world.
opening a file that doesn't exist
example.c:24 in main: fd = open("file-that-does-not-exist.xt", O_RDONLY): [2]: No such file or directory
I’ve been using a Garmin Fenix 6x for a couple of weeks and thought it might be interesting to put together a short review.
Is it really a smartwatch?
I think it’s a misnomer to call the Fenix a “smartwatch”. I would call it a highly capable fitness tracker. That’s not a knock on the product; I really like it so far, but pretty much everything it does is centered around either fitness tracking or navigation. If you browse around the “Connect IQ” store, mostly you’ll find (a) watch faces, (b) fitness apps, and (c) navigation apps. It’s not able to control your phone (for the most part; there are some apps available that offer remote camera control and some other limited features); you can’t check your email on it, or send text messages, and you’ll never find a watch version of any major smartphone app.
So if you’re looking for a smartwatch, maybe look elsewhere. But if you’re looking for a great fitness tracker, this just might be your device.
Things I will not talk about
I don’t listen to music when I exercise. If I’m inside, I’m watching a video on a streaming service, and if I’m outside, I want to be able to hear my surroundings. So I won’t be looking at any aspects of music support on the Fenix.
All the data in one place
One of the things I really like about the Fenix is that I now have more of my activity and health data in one place.
As part of my exercise a use a Schwinn IC4 spin bike. Previously, I was using a Fitbit Charge 5, which works fine but meant exercise metrics ended up in multiple places: while I could collect heart rate with the Fitbit, to collect cycling data like cadence, power, etc, I needed to use another app on my phone (I used Wahoo Fitness). Additionally, Fitbit doesn’t support sharing data with Apple Health, so there wasn’t a great way to see a unified view of things.
This has all changed with the Fenix:
First and probably most importantly, the Fenix is able to utilize the sensor on the IC4 directly, so cadence/speed/distance data is collected in the same place as heart rate data.
Through the magic of the Gymnasticon project, the Fenix is also able to collect power data from the bike.
The Fenix is also great at tracking my outside bike rides, and of course providing basic heart rate and time tracking of my strength and PT workouts.
All of this means that Garmin’s tools (both their app and the Garmin Connect website) provide a great unified view of my fitness activities.
Notifications
This is an area in which I think there is a lot of room for improvement.
Like any good connected watch, you can configure your Fenix to receive notifications from your phone. Unfortunately, this is an all-or-nothing configuration; there’s no facility for blocking or selecting notifications from specific apps.
I usually have my phone in do-not-disturb mode, so notifications from Google or the New York Times app don’t interrupt me, but they show up in the notification center when I check for anything interesting. With my Fenix connected, I get interrupted every time something happens.
Having the ability to filter which notifications get sent to the watch would be an incredibly helpful feature.
Battery life
One of the reasons I have the 6x instead of the 6 is the increased battery size that comes along with the bigger watch. While the advertising touts a battery life of “up to 21 days with activity tracking and 24/7 wrist-based heart rate monitoring”, I’ve been seeing battery life closer to 1 week under normal use (which includes probably 10-20 miles of GPS-tracked bike rides a week).
I’ve been using the pulse oximeter at night, but I understand that can have a substantial contribution to battery drain; I’ve disabled it for now and I’ll update this post if it turns out that has a significant impact on battery life.
One of the reasons that the Fenix is able to get substantially better battery life than the Apple Watch is that the screen is far, far dimmer. By default, the screen brightness is set to 20%; you can increase that, but you’ll consume substantially more power by doing so. In well lit areas – outdoors, or under office lighting – the display is generally very easy to read even with the backlight low.
Ease of use
It’s a mixed bag.
The basic watch and fitness tracking functionality is easy to use, and I like the fact that it uses physical buttons rather than a touch screen (I’ve spent too much time struggling with touch screens in winter). The phone app itself is relatively easy to use, although the “Activities & Apps” screen has the bad habit of refreshing while you’re trying to use it.
I have found Garmin’s documentation to be very good, and highly search optimized. In most cases, when I’ve wanted to know how to do something on my watch I’ve been able to search for it on Google, and:
Garmin’s manual is usually the first result
The instructions are on point and clearly written
For example, I wanted to know how to remove an activity from the list of favorite activities, so I searched for garmin remove activity from favorites, which led me directly to this documentation.
This was exactly the information I needed. I’ve had similar success with just about everything I’ve searched for.
The Garmin Connect app and website are both generally easy to use and well organized. There is an emphasis on “social networking” aspects (share your activities! Join a group! Earn badges!) in which I have zero interest, and I wish there was a checkbox to simply disable those parts of the UI.
The place where things really fall over is the “IQ Connect” app store. There are many apps and watch faces there that require some sort of payment, but there’s no centralized payment processing facility so you end up getting sent to random payment processors all over the place depending on what the software author selected…and price information simply isn’t displayed in the app store at all unless an author happens to include it in the product description.
The UI for configuring custom watch faces is awful; it’s a small step up from someone just throwing a text editor at you and telling you to edit a file. For this reason I’ve mostly stuck with Garmin-produced watch faces (the built-in ones and a few from the app store), which tend to have high visual quality but aren’t very configurable.
Some random technical details
While Garmin doesn’t provide any Linux support at all, you can plug the watch into your Linux system and access the watch filesystem using any MTP client, including Gnome’s GVFS. While this isn’t going to replace your phone app, it does give you reasonably convenient access to activity tracking data (as .fit files).
The Fenix ships with reasonably complete US maps. I haven’t had the chance to assess their coverage of local hiking trails. You can load maps from the OpenStreetMap project, although the process for doing so is annoyingly baroque.
It is easy to load GPX tracks from your favorite hiking website onto the watch using the Garmin Connect website or phone app.
Wrapping up
I’m happy with the watch. It is a substantial upgrade from my Charge 5 in terms of fitness tracking, and aesthetically I like it as much as the Seiko SNJ025 I was previously wearing. It’s not a great smartwatch, but that’s not what I was looking for, and the battery life is much better than actual smart watches from Apple and Samsung.
A digression, in which I yell at All Trails
This isn’t a Garmin or Fenix issue, but I’d like to specially recognize All Trails for making the process of exporting a GPX file to Garmin Connect as painful as possible. You can’t do it at all from the phone app, so the process is something like:
Use the All Trails app to find a hike you like
Decide you want to send it to your watch
Open a browser on your phone, go to https://alltrails.com, and log in (again, even though you were already logged in on the app)
Find the hike again
Download the GPX
Open the downloads folder
Open the GPX file
Click the “share” button
Find the Garmin Connect app
That is…completely ridiculous. The “Share” button in the All Trails app should provide an option to share the GPX version of the route so the above process could be collapsed into a single step. All Trails, why do you hate your users so much?
In this question, August Vrubel has some C code that sets up a tun interface and then injects a packet, but the packet seemed to disappear into the ether. In this post, I’d like to take a slightly extended look at my answer because I think it’s a great opportunity for learning a bit more about performing network diagnostics.
A problem with the original code is that it creates the interface, sends the packet, and tears down the interface with no delays, making it very difficult to inspect the interface configuration, perform packet captures, or otherwise figure out what’s going on.
In order to resolve those issues, I added some prompts before sending the packet and before tearing down the tun interface (and also some minimal error checking), giving us:
If we try running this as a regular user, it will simply fail (which confirms that at least some of our error handling is working correctly):
$ ./sendpacket
ioctl(fd, TUNSETIFF, (void *)&ifr)(@ sendpacket-pause.c:33): Operation not permitted
We need to run it as root:
$ sudo ./sendpacket
interface is up
The interface is up prompt means that the code has configured the interface but has not yet sent the packet. Let’s take a look at the interface configuration:
$ ip addr show tun0
3390: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UNKNOWN group default qlen 500 link/none
inet 172.30.0.1/32 scope global tun0
valid_lft forever preferred_lft forever
inet6 fe80::c7ca:fe15:5d5c:2c49/64 scope link stable-privacy
valid_lft forever preferred_lft forever
The code will emit a TCP SYN packet targeting address 192.168.255.8, port 10001. In another terminal, let’s watch for that on all interfaces. If we start tcpdump and press RETURN at the interface is up prompt, we’ll see something like:
# tcpdump -nn -i any port 1000122:36:35.336643 tun0 In IP 172.30.0.1.41626 > 192.168.255.8.10001: Flags [S], seq 2148230009, win 64240, options [mss 1460,sackOK,TS val 1534484436 ecr 0,nop,wscale 7], length 0
And indeed, we see the problem that was described: the packet enters the system on tun0, but never goes anywhere else. What’s going on?
Introducing pwru (Packet, Where are you?)
pwru is a nifty utility written by the folks at Cilium that takes advantage of eBPF to attach traces to hundreds of kernel functions to trace packet processing through the Linux kernel. It’s especially useful when packets seem to be getting dropped with no obvious explanation. Let’s see what it can tell us!
A convenient way to run pwru is using their official Docker image. We’ll run it like this, filtering by protocol and destination port so that we only see results relating to the synthesized packet created by the sendpacket.c code:
It looks like the synthesized packet data includes a bad checksum. We could update the code to correctly calculate the checksum…or we could just use Wireshark and have it tell us the correct values. Because this isn’t meant to be an IP networking primer, we’ll just use Wireshark, which gives us the following updated code:
Specifically, the packet is being dropped as a “martian source”, which means a packet that has a source address that is invalid for the interface on which it is being received. Unlike the previous error, we can actually get kernel log messages about this problem. If we had the log_martians sysctl enabled for all interfaces:
sysctl -w net.ipv4.conf.all.log_martians=1
Or if we enabled it specifically for tun0 after the interface is created:
sysctl -w net.ipv4.conf.tun0.log_martians=1
We would see the following message logged by the kernel:
Feb 14 12:14:03 madhatter kernel: IPv4: martian source 192.168.255.8 from 172.30.0.1, on dev tun0
We’re seeing this particular error because tun0 is configured with address 172.30.0.1, but it claims to be receiving a packet with the same source address from “somewhere else” on the network. This is a problem because we would never be able to reply to that packet (our replies would get routed to the local host). To deal with this problem, we can either change the source address of the packet, or we can change the IP address assigned to the tun0 interface. Since changing the source address would mean mucking about with checksums again, let’s change the address of tun0:
My internet service provider (FIOS) doesn’t yet (sad face) offer IPv6 capable service, so I’ve set up an IPv6 tunnel using the Hurricane Electric tunnel broker. I want to provide IPv6 connectivity to multiple systems in my house, but not to all systems in my house 1. In order to meet those requirements, I’m going to set up the tunnel on the router, and then expose connectivity over an IPv6-only VLAN. In this post, we’ll walk through the steps necessary to set that up.
Parts of this post are going to be device specific: for example, I’m using a Ubiquiti EdgeRouter X as my Internet router, so the tunnel setup is going to be specific to that device. The section about setting things up on my Linux desktop will be more generally applicable.
This shows how to set up the IPv6 VLAN interface under Linux using nmcli.
What we know
When you set up an IPv6 tunnel with hurricane electric, you receive several bits of information. We care in particular about the following (the IPv6 addresses and client IPv4 addresses here have been munged for privacy reasons):
IPv6 Tunnel Endpoints
Server IPv4 Address
209.51.161.14
Server IPv6 Address
2001:470:1236:1212::1/64
Client IPv4 Address
1.2.3.4
Client IPv6 Address
2001:470:1236:1212::2/64
Routed IPv6 Prefixes
Routed /64
2001:470:1237:1212::/64
We’ll refer back to this information as we configured things later on.
Configure the EdgeRouter
Create the tunnel interface
The first step in the process is to create a tunnel interface – that is, an interface that looks like an ordinary network interface, but is in fact encapsulating traffic and sending it to the tunnel broker where it will unpacked and sent on its way.
I’ll be creating a SIT tunnel, which is designed to “interconnect isolated IPv6 networks” over an IPv4 connection.
I start by setting the tunnel encapsulation type and assigning an IPv6 address to the tunnel interface. This is the “Client IPv6 Address” from the earlier table:
set interfaces tunnel tun0 encapsulation sit
set interfaces tunnel tun0 address 2001:470:1236:1212::2/64
Next I need to define the local and remote IPv4 endpoints of the tunnel. The remote endpoint is the “Server IPv4” address. The value 0.0.0.0 for the local-ip option means “whichever source address is appropriate for connecting to the given remote address”:
set interfaces tunnel tun0 remote-ip 209.51.161.14
set interfaces tunnel tun0 local-ip 0.0.0.0
Finally, I associate some firewall rulesets with the interface. This is import because, unlike IPv4, as you assign IPv6 addresses to internal devices they will be directly connected to the internet. With no firewall rules in place you would find yourself inadvertently exposing services that previously were “behind” your home router.
set interfaces tunnel tun0 firewall in ipv6-name WANv6_IN
set interfaces tunnel tun0 firewall local ipv6-name WANv6_LOCAL
I’m using the existing WANv6_IN and WANv6_LOCAL rulesets, which by default block all inbound traffic. These correspond to the following ip6tables chains:
root@ubnt:~# ip6tables -S WANv6_IN
-N WANv6_IN
-A WANv6_IN -m comment --comment WANv6_IN-10 -m state --state RELATED,ESTABLISHED -j RETURN
-A WANv6_IN -m comment --comment WANv6_IN-20 -m state --state INVALID -j DROP
-A WANv6_IN -m comment --comment "WANv6_IN-10000 default-action drop" -j LOG --log-prefix "[WANv6_IN-default-D]"
-A WANv6_IN -m comment --comment "WANv6_IN-10000 default-action drop" -j DROP
root@ubnt:~# ip6tables -S WANv6_LOCAL
-N WANv6_LOCAL
-A WANv6_LOCAL -m comment --comment WANv6_LOCAL-10 -m state --state RELATED,ESTABLISHED -j RETURN
-A WANv6_LOCAL -m comment --comment WANv6_LOCAL-20 -m state --state INVALID -j DROP
-A WANv6_LOCAL -p ipv6-icmp -m comment --comment WANv6_LOCAL-30 -j RETURN
-A WANv6_LOCAL -p udp -m comment --comment WANv6_LOCAL-40 -m udp --sport 547 --dport 546 -j RETURN
-A WANv6_LOCAL -m comment --comment "WANv6_LOCAL-10000 default-action drop" -j LOG --log-prefix "[WANv6_LOCAL-default-D]"
-A WANv6_LOCAL -m comment --comment "WANv6_LOCAL-10000 default-action drop" -j DROP
As you can see, both rulesets block all inbound traffic by default unless it is related to an existing outbound connection.
Create a vlan interface
I need to create a network interface on the router that will be the default gateway for my local IPv6-only network. From the tunnel broker, I received the CIDR 2001:470:1237:1212::/64 for local use, so:
I’ve decided to split this up into smaller networks (because a /64 has over 18 quintillion available addresses). I’m using /110 networks in this example, which means I will only ever be able to have 262,146 devices on each network (note that the decision to use a smaller subnet impacts your choices for address autoconfiguration; see RFC 7421 for the relevant discussion).
I’m using the first /110 network for this VLAN, which comprises addresses 2001:470:1237:1212::1 through 2001:470:1237:1212::3:ffff. I’ll use the first address as the router address.
I’ve arbitrarily decided to use VLAN id 10 for this purpose.
To create an interface for VLAN id 10 with address 2001:470:1237:1212::1/110, we use the set interfaces ... vif command:
set interfaces switch switch0 vif 10 address 2001:470:1237:1212::1/110
Configure the default IPv6 route
We don’t receive router advertisements over the IPv6 tunnel, which means we need to explicitly configure the IPv6 default route. The default gateway will be the “Server IPv6 Address” we received from the tunnel broker.
set protocol static route6 ::/0 next-hop 2001:470:1236:1212::1
Enable router advertisements
IPv6 systems on our local network will use the neighbor discovery protocol to discover the default gateway for the network. Support for this service is provided by RADVD, and we configure it using the set interfaces ... ipv6 router-advert command:
set interfaces switch switch0 vif 10 ipv6 router-advert send-advert true
set interfaces switch switch0 vif 10 ipv6 router-advert managed-flag true
set interfaces switch switch0 vif 10 ipv6 router-advert prefix ::/110
The managed-flag setting corresponds to the RADVD AdvManagedFlag configuration setting, which instructs clients to use DHCPv6 for address autoconfiguration.
Configure the DHCPv6 service
While in theory it is possible for clients to assign IPv6 addresses without the use of a DHCP server using stateless address autoconfiguration, this requires that we’re using a /64 subnet (see e.g. RFC 7421). There is no such limitation when using DHCPv6.
set service dhcpv6-server shared-network-name VLAN10 subnet 2001:470:1237:1212::/110 address-range start 2001:470:1237:1212::10 stop 2001:470:1237:1212::3:ffff
set service dhcpv6-server shared-network-name VLAN10 subnet 2001:470:1237:1212::/110 name-server 2001:470:1237:1212::1
set service dhcpv6-server shared-network-name VLAN10 subnet 2001:470:1237:1212::/110 domain-search house
set service dhcpv6-server shared-network-name VLAN10 subnet 2001:470:1237:1212::/110 lease-time default 86400
Here I’m largely setting things up to mirror the configuration of the IPv4 dhcp server for the name-server, domain-search, and lease-time settings. I’m letting the DHCPv6 server allocate pretty much the entire network range, with the exception of the first 10 addresses.
Commit the changes
After making the above changes they need to be activated:
commit
Verify the configuration
This produces the following interface configuration for tun0:
13: tun0@NONE: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000
link/sit 0.0.0.0 peer 209.51.161.14
inet6 2001:470:1236:1212::2/64 scope global
valid_lft forever preferred_lft forever
inet6 fe80::c0a8:101/64 scope link
valid_lft forever preferred_lft forever
inet6 fe80::6c07:49c7/64 scope link
valid_lft forever preferred_lft forever
And for switch0.10:
ubnt@ubnt:~$ ip addr show switch0.10
14: switch0.10@switch0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 78:8a:20:bb:05:db brd ff:ff:ff:ff:ff:ff
inet6 2001:470:1237:1212::1/110 scope global
valid_lft forever preferred_lft forever
inet6 fe80::7a8a:20ff:febb:5db/64 scope link
valid_lft forever preferred_lft forever
And the following route configuration:
ubnt@ubnt:~$ ip -6 route | grep -v fe80
2001:470:1236:1212::/64 dev tun0 proto kernel metric 256 pref medium
2001:470:1237:1212::/110 dev switch0.10 proto kernel metric 256 pref medium
default via 2001:470:1236:1212::1 dev tun0 proto zebra metric 1024 pref medium
We can confirm things are properly configured by accessing a remote service that reports our ip address:
In my home network, devices in my office connect to a switch, and the switch connects back to the router. I need to configure the switch (an older Netgear M4100-D12G) to pass the VLAN on to the desktop.
Add vlan 10 to the vlan database with name ipv6net0
I start by defining the VLAN in the VLAN database:
vlan database
vlan 10
vlan name 10 ipv6net0
exit
Configure vlan 10 as a tagged member of ports 1-10
Next, I configure the switch to pass VLAN 10 as a tagged VLAN on all switch interfaces:
With the above configuration in place, traffic on VLAN 10 will arrive on my Linux desktop (which is connected to the switch we configured in the previous step). I can use nmcli, the NetworkManager CLI, to add a VLAN interface (I’m using Fedora 37, which uses NetworkManager to manage network interface configuration; other distributions may have different tooling).
The following command will create a connection named vlan10. Bringing up the connection will create an interface named vlan10, configured to receive traffic on VLAN 10 arriving on eth0:
nmcli con add type vlan con-name vlan10 ifname vlan10 dev eth0 id 10 ipv6.method auto
nmcli con up vlan10
This produces the following interface configuration:
$ ip addr show vlan10
7972: vlan10@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 2c:f0:5d:c9:12:a9 brd ff:ff:ff:ff:ff:ff
inet6 2001:470:1237:1212::2:c19a/128 scope global dynamic noprefixroute
valid_lft 85860sec preferred_lft 53460sec
inet6 fe80::ced8:1750:d67c:2ead/64 scope link noprefixroute
valid_lft forever preferred_lft forever
And the following route configuration:
$ ip -6 route show | grep vlan10
2001:470:1237:1212::2:c19a dev vlan10 proto kernel metric 404 pref medium
2001:470:1237:1212::/110 dev vlan10 proto ra metric 404 pref medium
fe80::/64 dev vlan10 proto kernel metric 1024 pref medium
default via fe80::7a8a:20ff:febb:5db dev vlan10 proto ra metric 404 pref medium
We can confirm things are properly configured by accessing a remote service that reports our ip address:
Some services (Netflix is a notable example) block access over the IPv6 tunnels because it breaks their geolocation process and prevents them from determining your country of origin. I don’t want to break things for other folks in my house just because I want to play with IPv6. ↩︎
The RDO community is pleased to announce the general availability of the RDO build for OpenStack Zed for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Zed is the 26th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world. As with the Upstream release, this release of RDO is dedicated to Ilya Etingof who was an upstream and RDO contributor.
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
For the Zed cycle, TripleO project will maintain and validate stable Zed branches. As for the rest of packages, RDO will update and publish the releases created during the maintenance cycle.
Contributors During the Zed cycle, we saw the following new RDO contributors:
Miguel Garcia Cruces
Michael Johnson
René Ribaud
Paras Babbar
Maurício Harley
Jesse Pretorius
Francesco Pantano
Carlos Eduardo
Arun KV
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 57 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and redhat-website repositories:
Adriano Vieira Petrich
Alan Bishop
Alan Pevec
Alfredo Moralejo Alonso
Amol Kahat
Amy Marrich
Ananya Banerjee
Arun KV
Arx Cruz
Bhagyashri Shewale
Carlos Eduardo
Chandan Kumar
Cédric Jeanneret
Daniel Pawlik
Dariusz Smigiel
Douglas Viroel
Emma Foley
Eric Harney
Fabien Boucher
Francesco Pantano
Gregory Thiemonge
Jakob Meng
Jesse Pretorius
Jiří Podivín
Joel Capitao
Jon Schlueter
Julia Kreger
Karolina Kula
Leif Madsen
Lon Hohberger
Luigi Toscano
Marios Andreou
Martin Kopec
Mathieu Bultel
Matthias Runge
Maurício Harley
Michael Johnson
Miguel Garcia Cruces
Nate Johnston
Nicolas Hicher
Paras Babbar
Pooja Jadhav
Rabi Mishra
Rafael Castillo
René Ribaud/780
Riccardo Pittau
Ronelle Landy
Sagi Shnaidman
Sandeep Yadav
Sean Mooney
Shreshtha Joshi
Slawomir Kaplonski
Steve Baker
Takashi Kajinami
Tobias Urdin
Tristan De Cacqueray
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Antelope.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC IRC is also an excellent place to find and give help. We also welcome comments and requests on the CentOS devel mailing list and the CentOS and TripleO IRC channels (#centos, #centos-devel in Libera.Chat network, and #tripleo on OFTC), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and #tripleo on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
In today’s post, we look at KeyOxide, a service that allows you to cryptographically assert ownership of online resources using your GPG key. Some aspects of the service are less than obvious; in response to some questions I saw on Mastodon I though I would put together a short guide to making use of the service.
We’re going to look at the following high-level tasks:
The first thing you need to do is set up a GPG1 keypair and publish it to a keyserver (or a WKD endpoint). There are many guides out there that step you through the process (for example, GitHub’s guide on Generating a new GPG key), but if you’re in a hurry and not particularly picky, read on.
This assumes that you’re using a recent version of GPG; at the time of this writing, the current GPG release is 2.3.8, but these instructions seem to work at least with version 2.2.27.
Generate a new keypair using the --quick-gen-key option:
gpg --batch --quick-gen-key <your email address>
This will use the GPG defaults for the key algorithm (varies by version) and expiration time (the key never expires2).
When prompted, enter a secure passphrase.
GPG will create a keypair for you; you can view it after the fact by running:
Select the key export you just created, and select “upload”.
When prompted on the next page, select “Send Verification Email”. Your key won’t discoverable until you have received and responded to the verification email.
When you receive the email, select the verification link.
Now your key has been published! You can verify this by going to https://keys.openpgp.org/ and searching for your email address.
Step 3: Add a claim
You assert ownership of an online resource through a three step process:
Mark the online resource with your GPG key fingerprint. How you do this depends on the type of resource you’re claiming; e.g., for GitHub you create a gist with specific content, while for claiming a DNS domain you create a TXT record.
Add a notation to your GPG key with a reference to the claim created in the previous step.
Update your published key.
In this post we’re going to look at two specific examples; for other services, see the “Service providers” section of the KeyOxide documentation.
In order to follow any of the following instructions, you’re going to need to know your key fingerprint. When you show your public key by running gpg -k, you key fingerprint is the long hexadecimal string on the line following the line that starts with pub :
$ gpg -qk testuser@example.com
pub ed25519 2022-11-13 [SC] [expires: 2024-11-12]
EC03DFAC71DB3205EC19BAB1404E03D044EE706B <--- THIS LINE HERE
uid [ultimate] testuser@example.com
sub cv25519 2022-11-13 [E]
Add a claim to your GPG key
This is a set of common instructions that we’ll use every time we need to add a claim to our GPG key.
Edit your GPG key using the --edit-key option:
gpg --edit-key <your email address>
This will drop you into the GPG interactive key editor.
Select a user id on which to operate using the uid command. If you created your key following the instructions earlier in this post, then you only have a single user id:
gpg> uid 1
Add an annotation to the key using the notation command:
gpg> notation
When prompted, enter the notation (the format of the notation depends on the service you’re claiming; see below for details). For example, if we’re asserting a Mastodon identity at hachyderm.io, we would enter:
Enter the notation: proof@ariadne.id=https://hachyderm.io/@testuser
Alternately, you can configure gpg so that you can publish your key from the command line. Create or edit $HOME/.gnupg/gpg.conf and add the following line:
keyserver hkps://keys.openpgp.org
Now every time you need to update the published version of your key:
Upload your public key using the --send-keys option along with your key fingerprint, e.g:
On your favorite Mastodon server, go to your profile and select “Edit profile”.
Look for the “Profile metadata section”; this allows you to associate four bits of metadata with your Mastodon profile. Assuming that you still have a slot free, give it a name (it could be anything, I went with “Keyoxide claim”), and for the value enter:
openpgp4fpr:<your key fingerprint>
E.g., given the gpg -k output shown above, I would enter:
Now, add the claim to your GPG key by adding the notation proof@ariadne.id=https://<your mastodon server>/@<your mastodon username. I am @larsks@hachyderm.io, so I would enter:
You’ll note that none of the previous steps required interacting with KeyOxide. That’s because KeyOxide doesn’t actually store any of your data: it just provides a mechanism for visualizing and verifying claims.
You can look up an identity by email address or by GPG key fingerprint.
The pedantic among you will already be writing to me about how PGP is the standard and GPG is an implementation of that standard, but I’m going to stick with this nomenclature for the sake of simplicity. ↩︎
For some thoughts on key expiration, see this question on the Information Security StackExchange. ↩︎
Hello, future me. This is for you next time you want to do this.
When setting up the CI for a project I will sometimes end up with a tremendous clutter of workflow runs. Sometimes they have embarrassing mistakes. Who wants to show that to people? I was trying to figure out how to bulk delete workflow runs from the CLI, and I came up with something that works:
gh run list --json databaseId -q '.[].databaseId' |
xargs -IID gh api \
"repos/$(gh repo view --json nameWithOwner -q .nameWithOwner)/actions/runs/ID" \
-X DELETE
This will delete all (well, up to 20, or whatever you set in --limit) your workflow runs. You can add flags to gh run list to filter runs by workflow or by triggering user.
We are working with an application that produces resource utilization reports for clients of our OpenShift-based cloud environments. The developers working with the application have been reporting mysterious issues concerning connection timeouts between the application and the database (a MariaDB instance). For a long time we had only high-level verbal descriptions of the problem (“I’m seeing a lot of connection timeouts!”) and a variety of unsubstantiated theories (from multiple sources) about the cause. Absent a solid reproducer of the behavior in question, we looked at other aspects of our infrastructure:
Networking seemed fine (we weren’t able to find any evidence of interface errors, packet loss, or bandwidth issues)
Storage in most of our cloud environments is provided by remote Ceph clusters. In addition to not seeing any evidence of network problems in general, we weren’t able to demonstrate specific problems with our storage, either (we did spot some performance variation between our Ceph clusters that may be worth investigating in the future, but it wasn’t the sort that would cause the problems we’re seeing)
My own attempts to reproduce the behavior using mysqlslap did not demonstrate any problems, even though we were driving a far larger number of connections and queries/second in the benchmarks than we were in the application.
What was going on?
I was finally able to get my hands on container images, deployment manifests, and instructions to reproduce the problem this past Friday. After working through some initial errors that weren’t the errors we were looking for (insert Jedi hand gesture here), I was able to see the behavior in practice. In a section of code that makes a number of connections to the database, we were seeing:
Failed to create databases:
Command returned non-zero value '1': ERROR 2003 (HY000): Can't connect to MySQL server on 'mariadb' (110)
#0 /usr/share/xdmod/classes/CCR/DB/MySQLHelper.php(521): CCR\DB\MySQLHelper::staticExecuteCommand(Array)
#1 /usr/share/xdmod/classes/CCR/DB/MySQLHelper.php(332): CCR\DB\MySQLHelper::staticExecuteStatement('mariadb', '3306', 'root', 'pass', NULL, 'SELECT SCHEMA_N...')
#2 /usr/share/xdmod/classes/OpenXdmod/Shared/DatabaseHelper.php(65): CCR\DB\MySQLHelper::databaseExists('mariadb', '3306', 'root', 'pass', 'mod_logger')
#3 /usr/share/xdmod/classes/OpenXdmod/Setup/DatabaseSetupItem.php(39): OpenXdmod\Shared\DatabaseHelper::createDatabases('root', 'pass', Array, Array, Object(OpenXdmod\Setup\Console))
#4 /usr/share/xdmod/classes/OpenXdmod/Setup/DatabaseSetup.php(109): OpenXdmod\Setup\DatabaseSetupItem->createDatabases('root', 'pass', Array, Array)
#5 /usr/share/xdmod/classes/OpenXdmod/Setup/Menu.php(69): OpenXdmod\Setup\DatabaseSetup->handle()
#6 /usr/bin/xdmod-setup(37): OpenXdmod\Setup\Menu->display()
#7 /usr/bin/xdmod-setup(22): main()
#8 {main}
Where 110 is ETIMEDOUT, “Connection timed out”.
The application consists of two Deployment resources, one that manages a MariaDB pod and another that manages the application itself. There are also the usual suspects, such as PersistentVolumeClaims for the database backing store, etc, and a Service to allow the application to access the database.
While looking at this problem, I attempted to look at the logs for the application by running:
kubectl logs deploy/moc-xdmod
But to my surprise, I found myself looking at the logs for the MariaDB container instead…which provided me just about all the information I needed about the problem.
How do Deployments work?
To understand what’s going on, let’s first take a closer look at a Deployment manifest. The basic framework is something like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example
spec:
selector:
matchLabels:
app: example
strategy:
type: Recreate
template:
metadata:
labels:
app: example
spec:
containers:
- name: example
image: docker.io/alpine:latest
command:
- sleep
- inf
There are labels in three places in this manifest:
The Deployment itself has labels in the metadata section.
There are labels in spec.template.metadata that will be applied to Pods spawned by the Deployment.
There are labels in spec.selector which, in the words of [the documentation]:
defines how the Deployment finds which Pods to manage
It’s not spelled out explicitly anywhere, but the spec.selector field is also used to identify to which pods to attach when using the Deployment name in a command like kubectl logs: that is, given the above manifest, running kubectl logs deploy/example would look for pods that have label app set to example.
With this in mind, let’s take a look at how our application manifests are being deployed. Like most of our applications, this is deployed using Kustomize. The kustomization.yaml file for the application manifests looked like this:
That commonLabels statement will apply the label app: xdmod to all of the resources managed by the kustomization.yaml file. The Deployments looked like this:
The problem here is that when these are processed by kustomize, the app label hardcoded in the manifests will be replaced by the app label defined in the commonLabels section of kustomization.yaml. When we run kustomize build on these manifests, we will have as output:
In other words, all of our pods will have the same labels (because the spec.template.metadata.labels section is identical in both Deployments). When I run kubectl logs deploy/moc-xdmod, I’m just getting whatever the first match is for a query that is effectively the same as kubectl get pod -l app=xdmod.
So, that’s what was going on with the kubectl logs command.
How do services work?
A Service manifest in Kubernetes looks something like this:
Here, spec.selector has a function very similar to what it had in a Deployment: it selects pods to which the Service will direct traffic. From the documentation, we know that a Service proxy will select a backend either in a round-robin fashion (using the legacy user-space proxy) or in a random fashion (using the iptables proxy) (there is also an IPVS proxy mode, but that’s not available in our environment).
Given what we know from the previous section about Deployments, you can probably see what’s going on here:
There are multiple pods with identical labels that are providing distinct services
For each incoming connection, the service proxy selects a Pod based on the labels in the service’s spec.selector.
With only two pods involved, there’s a 50% chance that traffic targeting our MariaDB instance will in fact be directed to the application pod, which will simply drop the traffic (because it’s not listening on the appropriate port).
We can see the impact of this behavior by running a simple loop that attempts to connect to MariaDB and run a query:
Here we can see that connection time is highly variable, and we occasionally hit the 10 second timeout imposed by the timeout call.
Solving the problem
In order to resolve this behavior, we want to ensure (a) that Pods managed by a Deployment are uniquely identified by their labels and that (b) spec.selector for both Deployments and Services will only select the appropriate Pods. We can do this with a few simple changes.
It’s useful to apply some labels consistently across all of the resource we generate, so we’ll keep the existing commonLabels section of our kustomization.yaml:
commonLabels:
app: xdmod
But then in each Deployment we’ll add a component label identifying the specific service, like this:
In the above output, you can see that kustomize has combined the commonLabel definition with the labels configured individually in the manifests. With this change, spec.selector will now select only the pod in which MariaDB is running.
We’ll similarly modify the Service manifest to look like:
This post is mostly for myself: I find the Traefik documentation hard to navigate, so having figured this out in response to a question on Stack Overflow, I’m putting it here to help it stick in my head.
The question asks essentially how to perform port-based routing of requests to containers, so that a request for http://example.com goes to one container while a request for http://example.com:9090 goes to a different container.
Creating entrypoints
A default Traefik configuration will already have a listener on port 80, but if we want to accept connections on port 9090 we need to create a new listener: what Traefik calls an entrypoint. We do this using the --entrypoints.<name>.address option. For example, --entrypoints.ep1.address=80 creates an entrypoint named ep1 on port 80, while --entrypoints.ep2.address=9090 creates an entrypoint named ep2 on port 9090. Those names are important because we’ll use them for mapping containers to the appropriate listener later on.
This gives us a Traefik configuration that looks something like:
We need to publish ports 80 and 9090 on the host in order to accept connections. Port 8080 is by default the Traefik dashboard; in this configuration I have it bound to localhost because I don’t want to provide external access to the dashboard.
Routing services
Now we need to configure our services so that connections on ports 80 and 9090 will get routed to the appropriate containers. We do this using the traefik.http.routers.<name>.entrypoints label. Here’s a simple example:
The command to run the formatting tests for the keystone project is:
tox -e pe8
Running this on Fedora35 failed for me with this error:
ERROR: pep8: could not install deps [-chttps://releases.openstack.org/constraints/upper/master, -r/opt/stack/keystone/test-requirements.txt, .[ldap,memcache,mongodb]]; v = InvocationError("/opt/stack/keystone/.tox/pep8/bin/python -m pip install -chttps://releases.openstack.org/constraints/upper/master -r/opt/stack/keystone/test-requirements.txt '.[ldap,memcache,mongodb]'", 1)
What gets swallowed up is the actual error in the install, and it has to do with the fact that the python dependencies are compiled against native libraries. If I activate the venv and run the command by hand, I can see the first failure. But if I look up at the previous output, I can see it, just buried a few screens up:
Error: pg_config executable not found.
A Later error was due to the compile step erroring out looking for lber.h:
In file included from Modules/LDAPObject.c:3:
Modules/common.h:15:10: fatal error: lber.h: No such file or directory
15 | #include
| ^~~~~~~~
compilation terminated.
error: command '/usr/bin/gcc' failed with exit code 1
To get the build to run, I need to install both libpq-devel and libldap-devel and now it fails like this:
File "/opt/stack/keystone/.tox/pep8/lib/python3.10/site-packages/pep257.py", line 24, in
from collections import defaultdict, namedtuple, Set
ImportError: cannot import name 'Set' from 'collections' (/usr/lib64/python3.10/collections/__init__.py)
This appears to be due to the version of python3 on my system (3.10) which is later than supported by upstream openstack. I do have python3.9 installed on my system, and can modify the tox.ini to use it by specifying the basepython version.
Edit /etc/keystone/keystone.conf to support domin specific backends and back them with file config. When you are done, your identity section should look like this.
Create the corresponding directory for the new configuration files.
sudo mkdir /etc/keystone/domains/
Add in a configuration file for your LDAP server. Since I called my domain freeipa I have to name the config file /etc/keystone/domains/keystone.freeipa.conf
The RDO community is pleased to announce the general availability of the RDO build for OpenStack Yoga for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Yoga is the 25th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The release is already available on the CentOS mirror network:
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
Interesting things in the Yoga release include:
RDO Yoga is the first RDO version built and tested for CentOS Stream 9.
In order to ease transition from CentOS Stream 8, RDO Yoga is also built and tested for CentOS Stream 8. Note that next release of RDO will be available only for CentOS Stream 9.
Since the Xena development cycle, TripleO follows the Independent release model and will only maintain branches for selected OpenStack releases. In the case of Yoga, TripleO will not support the Yoga release. For TripleO users in RDO, this means that:
RDO Yoga will include packages for TripleO tested at OpenStack Yoga GA time.
Those packages will not be updated during the entire Yoga maintenance cycle.
RDO will not be able to included patches required to fix bugs in TripleO on RDO Yoga.
The lifecycle for the non-TripleO packages will follow the code merged and tested in upstream stable/yoga branches.
There will not be any TripleO Yoga container images built/pushed, so interested users will have to do their own container builds when deploying Yoga.
You can find details about this on the RDO Webpage
Contributors
During the Yoga cycle, we saw the following new RDO contributors:
Adriano Vieira Petrich
Andrea Bolognani
Dariusz Smigiel
David Vallee Delisle
Douglas Viroel
Jakob Meng
Lucas Alvares Gomes
Luis Tomas Bolivar
T. Nichole Williams
Karolina Kula
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 40 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and redhat-website repositories:
Adriano Vieira Petrich
Alan Bishop
Alan Pevec
Alex Schultz
Alfredo Moralejo
Amy Marrich (spotz)
Andrea Bolognani
Chandan Kumar
Daniel Alvarez Sanchez
Dariusz Smigiel
David Vallee Delisle
Douglas Viroel
Emma Foley
Gaël Chamoulaud
Gregory Thiemonge
Harald
Jakob Meng
James Slagle
Jiri Podivin
Joel Capitao
Jon Schlueter
Julia Kreger
Kashyap Chamarthy
Lee Yarwood
Lon Hohberger
Lucas Alvares Gomes
Luigi Toscano
Luis Tomas Bolivar
Martin Kopec
mathieu bultel
Matthias Runge
Riccardo Pittau
Sergey
Stephen Finucane
Steve Baker
Takashi Kajinami
T. Nichole Williams
Tobias Urdin
Karolina Kula
User otherwiseguy
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Zed.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has the users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC. IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS and TripleO IRC channels (#centos, #centos-devel in Libera Chat network, and #tripleo on OFTC), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and #tripleo on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
For the past week I worked on getting a Ironic standalone to run on an Ampere AltraMax server in our lab. As I recently was able to get a baremetal node to boot, I wanted to record the steps I went through.
Our base operating system for this install is Ubuntu 20.04.
The controller node has 2 Mellanox Technologies MT27710 network cards, each with 2 ports apiece.
I started by following the steps to install with the bifrost-cli. However, there were a few places where the installation assumes an x86_64 architecture, and I hard-swapped them to be AARCH64/ARM64 specific:
$ git diff HEAD
diff --git a/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Debian_family.yml b/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Debian_family.yml
index 18e281b0..277bfc1c 100644
--- a/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Debian_family.yml
+++ b/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Debian_family.yml
@@ -6,8 +6,8 @@ ironic_rootwrap_dir: /usr/local/bin/
mysql_service_name: mysql
tftp_service_name: tftpd-hpa
efi_distro: debian
-grub_efi_binary: /usr/lib/grub/x86_64-efi-signed/grubx64.efi.signed
-shim_efi_binary: /usr/lib/shim/shimx64.efi.signed
+grub_efi_binary: /usr/lib/grub/arm64-efi-signed/grubaa64.efi.signed
+shim_efi_binary: /usr/lib/shim/shimaa64.efi.signed
required_packages:
- mariadb-server
- python3-dev
diff --git a/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Ubuntu.yml b/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Ubuntu.yml
index 7fcbcd46..4d6a1337 100644
--- a/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Ubuntu.yml
+++ b/playbooks/roles/bifrost-ironic-install/defaults/required_defaults_Ubuntu.yml
@@ -26,7 +26,7 @@ required_packages:
- dnsmasq
- apache2-utils
- isolinux
- - grub-efi-amd64-signed
+ - grub-efi-arm64-signed
- shim-signed
- dosfstools
# NOTE(TheJulia): The above entry for dnsmasq must be the last entry in the
The long term approach to these is to make those variables architecture specific.
It took me several tries with -e variables until realized that it was not going to honor them. I did notice that the heart of the command was the Ansible call, which I ended up running directly:
You may notice that I added a -e with the baremetal-install-env.json file. That file had been created by the earlier CLI run., and contained the variables specific to my install. I also edited it to trigger the build of the ironic cleaning image.
With this ins place, I was able to enroll nodes using the Bifrost cli:
~/bifrost/bifrost-cli enroll ~/nodes.json
I prefer this to using my own script. However, my script checks for existence and thus can be run idempotently, unlike this one. Still, I like the file format and will likely script to it in the future.
WIth this, I was ready to try booting the nodes, but they hung as I reported in an earlier article.
The other place where the deployment is x86_64 specific is the iPXE binary. In a bifrost install on Ubuntu, the binary is called ipxe.efi, and it is placed in /var/lib/tftpboot/ipxe.efi. It is copied from the grub-ipxe package which places it in /boot/ipxe.efi. Although this package is not tagged as an x86_64 architecture (Debian/Ubuntu call it all) the file is architecture specific.
I went through the steps to fetch and install the latest one out of jammy which has an additional file: /boot/ipxe-arm64.efi. However, when I replaced the file /var/lib/tftpboot/ipxe.efi with this one, the baremetal node still failed to boot, although it did get a few steps further in the process.
The issue, as I understand it, is that the binary needs as set of drivers to set up the http request in the network interface cards, and the build in the Ubuntu package did not have that. Instead, I cloned the source git repo and compiled the binary directly. Roughly
git clone https://github.com/ipxe/ipxe.git
cd ipxe/src
make bin-arm64-efi/snponly.efi ARCH=arm64
The EFI_SIMPLE_NETWORK_PROTOCOL provides services to initialize a network interface,
transmit packets, receive packets, and close a network interface.
It seems the Mellanox cards support/require SNP. With this file in place, I was able to get the cleaning image to PXE boot.
I call this a spike as it has a lot of corners cut in it that I would not want to maintain in production. We’ll work with the distributions to get a viable version of ipxe.efi produced that can work for an array of servers, including Ampere’s. In the meantime, I need a strategy to handle building our own binary. I also plan on reworking the Bifrost variables to handle ARM64/AARCH64 along side x86_64; a single server should be able to handle both based on the Architecture flag sent in the initial DHCP request.
Note: I was not able to get the cleaning image to boot, as it had an issue with werkzeug and JSON. However, I had an older build of the IPA kernel and initrd that I used, and the node properly deployed and cleaned.
And yes, I plan on integrating Keystone in the future, too.
There are a handful of questions a user will (implicitly) ask when using your API:
What actions can I do against this endpoint?
How do I find the URLs for those actions?
What information do I need to provide in order to perform this action?
What permission do I need in order to perform this action.
Answering these questions can be automated. The user, and the tools they use, can discover the answers by working with the system. That is what I mean when I use the word “Discoverability.”
We missed some opportunities to answer these questions when we designed the APIs for Keystone OpenStack. I’d like to talk about how to improve on what we did there.
First I’d like to state what not to do.
Don’t make the user read the documentation and code to an external spec.
Never require a user to manually perform an operation that should be automated. Answering every one of those question can be automated. If you can get it wrong, you will get it wrong. Make it possible to catch errors as early as possible.
Lets start with the question: “What actions can I do against this endpoint?” In the case of Keystone, the answer would be some of the following:
Create, Read, Update and Delete (CRUD) Users, Groups of Users, Projects, Roles, and Catalog Items such as Services and Endpoints. You can also CRUD relationships between these entities. You can CRUD Entities for Federated Identity. You can CRUD Policy files (historical). Taken in total, you have the tools to make access control decisions for a wide array of services, not just Keystone.
The primary way, however, that people interact with Keystone is to get a token. Let’s use this use case to start. To Get a token, you make a POST to the $OS_AUTH_URL/v3/auth/tokens/ URL. The data
How would you know this? Only by reading the documentation. If someone handed you the value of their OS_AUTH_URL environment variable, and you looked at it using a web client, what would you get? Really, just the version URL. Assuming you chopped off the V3:
and the only URL in there is the version URL, which gives you back the same thing.
If you point a web browser at the service, the output is in JSON, even though the web browser told the server that it preferred HTML.
What could this look like: If we look at the API spec for Keystone: We can see that the various entities referred to Above hat fairly predictable URL forms. However, for this use case, we want a token, so we should, at a minimum, see the path to get to the token. Since this is the V3 API, we should See an entry like this:
Is this 100% of the solution? No. The Keystone API shows its prejudices toward PASSWORD based authentication, a very big antipattern. The Password goes in clear text into the middle of the JSON blob posted to this API. We trust in SSL/TLS to secure it over the wire, and have had to erase from logs and debugging. This is actually a step backwards from BASIC_AUTH in HTTP. All this aside, there is still no way to tell what you need to put into the body of the token request without reading the documentation….unless you know the magic of JSON-HOME.
Here is what you would need to do to get a list of the top level URLS, excluding all the ones that are templated, and thus require knowing an ID.
This would be the friendly list to return from the /v3 page. Or, if we wanted to streamline it a bit for human consumption, we could put a top level grouping around each of these APIs. A friendlier list would look like this (chopping off the /v3)
auth
assignment
catalog
federation
identity
limits
resource
assignment
policy
There are a couple ways to order the list. Alphabetical order is the simplest for an English speaker if they know what they are looking for. This won’t internationalize, and it won’t guide the user to the use cases that are most common. Thus, I put auth at the top, as that is, by far, the most common use case. The others I have organized based on a quick think-through from most to least common. I could easily be convinced to restructure this a couple different ways.
However, we are starting to trip over some of the other aspects of usability. We have provided the user with way more information than they need, or, indeed, can use at this point. Since none of those operations can be performed unauthenticated, we have lead the user astray; we should show them, at this stage, only what they can do in their current state. Thus: the obvious entry would be.
/v3/auth/tokens.
/v3/auth/OS-FEDERATION
As these are the only two directions they can go unauthenticated.
Lets continue on with the old-school version of a token request using the v3/auth/tokens resource, as that is the most common use case. How now does a user request a token? Depends on whether they want to use password or another token, or multifactor, and whether they want an unscoped token or a scoped token.
None of this information is in the JSON home. You have to read the docs.
If we were using straight HTML to render the response, we would expect a form. Something along the lines of:
There is, as of now, no standard way to put form data into JSON. However, there are numerous standards to chose from. One such standard is FormData API. JSON Scheme https://json-schema.org/. If we look at the API do, we get a table that specifies the name. Anything that is not a single value is specified as an object, which really means a JSON object which is a dictionary that can bee deeply nested. We can see the complexity in the above form, where the scope value determines what is meant by the project/domain name field. And these versions don’t allow for IDs to be used instead of the names for users, projects, or domains.
A lot of the custom approach here is dictated by the fact that Keystone does not accept standard authentication. The Password based token request could easily be replaced with BASIC-AUTH. Tokens themselves could be stored as session cookies, with the same timeouts as the token expiration. All of the One-Offs in Keystone make it more difficult to use, and require more application specific knowledge.
Many of these issues were straightened out when we started doing federation. Now, there is still some out-of-band knowledge required to use the Federated API, but this was due to concerns about information leaking that I am going to ignore for now. The approach I am going to describe is basically what is used by any app that allows you to log in from the different cloud providers Identity sources today.
From the /v3 page, a user should be able to select the identity provider that they want to use. This could require a jump to /v3/FEDERATION and then to /v3/FEDERATION/idp, in order to keep things namespaced, or the list could be expanded in the /v3 page if there is really nothing else that a user can do unauthenticated.
Let us assume a case where there are three companies that all share access to the cloud; Acme, Beta, and Charlie. The JSON response would be the same as the list identity providers API. The interesting part of the result is this one here:
Lets say that a given Identity provider supports multiple protocols. Here is where the user gets to chose which hone they want to use to try and authenticate. An HTTP GET on the link above would return that list: The documentation shows an example of an identity provider that supports saml2. Here is an expanded one that shows the set of protocols a user could expect in a private cloud running FreeIPA and Keycloak, or Active Directory and ADFS.
Lets ignore the actual response from the above links and assume that, if the user is unauthenticated, they merely get a link to where they can authenticate. /v3/OS-FEDERATION/identity_providers/{idp_id}/protocols/{protocol_id}/auth. The follow on link is a GET. Not a POST. There is no form Data required. The mapping resolves the users Domain Name/ID, so there is no need to provide that information, and the token is a Federated unscoped token.
The actual response contains the list of groups that a user belongs to. This is an artifact of the mapping, and it is useful for debugging. However, what the user has at this point is, effectively, an unscoped token. It is passed in the X-Subject-Token header, and not in the session cookie. However, for an HTML based workflow, and, indeed, for sane HTTP workflows against Keystone, a session scoped cookie containing the token would be much more useful.
With an unscoped token, a user can perform some operations against a Keystone server, but those operations are either read-only, operations specific to the user, or administrative actions specific to the Keystone server. For OpenStack, the vast majority of the time the user is going to Keystone to request a scoped token to use on one of the other services. As such, the user probably needs to convert the unscoped token shown above to a token scoped to a project. A very common setup has the user assigned to a single project. Even if they are scoped to multiple, it is unlikely that they are scoped to many. Thus, the obvious next step is to show the user a URL that will allow them to get a token scoped to a specific project.
A much friendlier URL scheme would be /v3/auth/projects which lists the set of projects a user can request a token for, and /v3/auth/project/{id} which lets a user request a scoped token for that project
However, even if we had such a URL pattern, we would need to direct the user to that URL. There are two distinct use cases. The first is the case where the user has just authenticated, and in the token response, they need to see the project list URL. A redirect makes the most sense, although the list of projects could also be in authentication response. However, the user might also be returning to the Keystone server from some other operation, still have the session cookie with the token in it, and start at the discovery page again. IN this case, the /v3/ response should show /v3/auth/projects/ in its list.
There is, unfortunately, one case where this would be problematic. With Hierarchical projects, a single assignment could allow a user to get a token for many projects. While this is a useful hack in practice, it means that the project list page could get extremely long. This is, unfortunately also the case with the project list page itself; projects may be nested, but the namespace needs to be flat, and listing projects will list all of them, only the parent-project ID distinguishes them. Since we do have ways to do path nesting in HTTP, this is a solvable problem. Lets lump the token request and the project list APIs together. This actually makes a very elegant solution;
Instead of /v3/auth/projects we put a link off the project page itelf back to /v3/auth/tokens but accepting the project ID as a URL parameter, like this: /v3/auth/tokens?project_id=abc123.
Of course, this means that there is a hidden mechanism now. If a user wants to look at any resource in Keystone, they can do so with an unscoped token, provided they have a role assignment on the project or domain that manages that object.
To this point we have discussed implicit answers to the questions of finding URLs and discovering what actions a user can perform. For the token request, is started discussing how to provide the answer to “What information do I need to provide in order to perform this action?” I think now we can state how to do that: the list page for any collection should either provide an inline form or a link to a form URL. The form provides the information in a format that makes sense for the content type. If the user does not have the permission to create the object, they should not see the form. If the form is on a separate link, a user that cannot create that object should get back a 403 error if they attempt to GET the URL.
If Keystone had been written to return HTML when hit by a browser instead of JSON, all of this navigation would have been painfully obvious. Instead, we subscribed to the point of view that UI was to be done by the Horizon server.
There still remains the last question: “What permission do I need in order to perform this action?” The user only thinks to answer this question when they come across an operation that they cannot perform. I’ll did deeper into this in the next article
Kolla creates an admin.rc file using the environment variables. I want to then use this in a terraform plan, but I’d rather not generate terrafoprm specific code for the Keystone login data. So, a simple python script converts from env vars to yaml.
I like to fiddle with Micropython, particularly on the Wemos D1 Mini, because these are such a neat form factor. Unfortunately, they have a cheap CH340 serial adapter on board, which means that from the perspective of Linux these devices are all functionally identical – there’s no way to identify one device from another. This by itself would be a manageable problem, except that the device names assigned to these devices aren’t constant: depending on the order in which they get plugged in (and the order in which they are detected at boot), a device might be /dev/ttyUSB0 one day and /dev/ttyUSB2 another day.
On more than one occasion, I have accidentally re-flashed the wrong device. Ouch.
A common solution to this problem is to create device names based on the USB topology – that is, assign names based on a device’s position in the USB bus: e.g., when attaching a new USB serial device, expose it at something like /dev/usbserial/<bus>/<device_path>. While that sounds conceptually simple, it took me a while to figure out the correct udev rules.
Looking at the available attributes for a serial device, we see:
In this output, we find that the device itself (at the top) doesn’t have any useful attributes we can use for creating a systematic device name. It’s not until we’ve moved up the device hierarchy to /devices/pci0000:00/0000:00:1c.0/0000:03:00.0/usb3/3-1/3-1.4/3-1.4.3 that we find topology information (in the busnum and devpath attributes). This complicates matters because a udev rule only has access to attributes defined directly on matching device, so we can’t right something like:
Here, my goal was to stash the busnum and devpath attributes in .USB_BUSNUM and .USB_DEVPATH, but this didn’t work: it matches device path /devices/pci0000:00/0000:00:1c.0/0000:03:00.0/usb3/3-1/3-1.4/3-1.4.3/3-1.4.3:1.0, which is:
We need to match the next device up the chain, so we need to make our match more specific. There are a couple of different options we can pursue; the simplest is probably to take advantage of the fact that the next device up the chain has SUBSYSTEMS=="usb" and DRIVERS="usb", so we could instead write:
Where (from the udev(7) man page), ? matches any single character and * matches zero or more characters, so this matches any device in which busnum has a non-empty value. We can test this rule out using the udevadm test command:
# udevadm test $(udevadm info --query=path --name=/dev/ttyUSB0)
[...]
.USB_BUSNUM=3
.USB_DEVPATH=1.4.3
[...]
This shows us that our rule is matching and setting up the appropriate variables. We can now use those in a subsequent rule to create the desired symlink:
And there have it. Now as long as I attach a specific device to the same USB port on my system, it will have the same device node. I’ve updated my tooling to use these paths (/dev/usbserial/3/1.4.3) instead of the kernel names (/dev/ttyUSB0), and it has greatly simplified things.
$ openstack server list -c ID -c Name -c Status+--------------------------------------+-------+--------+| ID | Name | Status |+--------------------------------------+-------+--------+| 7e087c31-7e9c-47f7-a4c4-ebcc20034faa | foo-4 | ACTIVE || 977fd250-75d4-4da3-a37c-bc7649047151 | foo-2 | ACTIVE || a1182f44-7163-4ad9-89ed-36611f75bac7 | foo-5 | ACTIVE || a91951b3-ff4e-46a0-a5fd-20064f02afc9 | foo-3 | ACTIVE || f0a62c20-2304-4c8c-aaf5-f5bc9d385b5f | foo-1 | ACTIVE |+--------------------------------------+-------+--------+
We'll use f0a62c20-2304-4c8c-aaf5-f5bc9d385b5f. That's the uuid of the server foo-1. For convenience, the server uuid and the resource ID used in openstack metric resource are the same.
This list shows the metrics associated with the instance.
You are done here.
Checking if ceilometer is running
$ ssh controller-0 -l root
$ podman ps --format "{{.Names}} {{.Status}}"| grep ceilometer
ceilometer_agent_central Up 2 hours ago
ceilometer_agent_notification Up 2 hours ago
On compute nodes, there should be ceilometer_agent_compute running
$ podman ps --format "{{.Names}} {{.Status}}"| grep ceilometer
ceilometer_agent_compute Up 2 hours ago
The metrics are being sent from ceilometer to a remote defined in
/var/lib/config-data/puppet-generated/ceilometer/etc/ceilometer/pipeline.yaml
, which may look similar to the following file
In this case, data is sent to both STF and Gnocchi. Next step is to check
if there are any errors happening. On controllers and computes, ceilometer
logs are found in /var/log/containers/ceilometer/.
The agent-notification.log shows logs from publishing data, as well as
errors if sending out metrics or logs fails for some reason.
If there are any errors in the log file, it is likely that metrics are not
being delivered to the remote.
In this case, it failes to send messages to the STF instance. The following
example shows the gnocchi api not responding or not being accessible
2021-11-16 10:38:07.707 16 ERROR ceilometer.publisher.gnocchi [-]<html><body><h1>503 Service Unavailable</h1>No server is available to handle this request.</body></html> (HTTP 503): gnocchiclient.exceptions.ClientException: <html><body><h1>503 Service Unavailable</h1>
For more gnocchi debugging, see the gnocchi section.
Gnocchi
Gnocchi sits on controller nodes and consists of three separate containers,
gnocchi_metricd, gnocchi_statsd, and gnocchi_api. The latter is for the
interaction with the outside world, such as ingesting metrics or returning
measurements.
Gnocchi metricd are used for re-calculating metrics, downsampling for lower
granularity, etc. Gnocchi logfiles are found under /var/log/containers/gnocchi
and the gnocchi API is hooked into httpd, thus the logfiles are
stored under /var/log/containers/httpd/gnocchi-api/. The corresponding files
there are either gnocchi_wsgi_access.log or gnocchi_wsgi_error.log.
In the case from above (ceilometer section), where ceilometer could not
send metrics to gnocchi, one would also observe log output for the
gnocchi API.
Retrieving metrics from Gnocchi
For a starter, let's see which resources there are.
openstack server list -c ID -c Name -c Status+--------------------------------------+-------+--------+| ID | Name | Status |+--------------------------------------+-------+--------+| 7e087c31-7e9c-47f7-a4c4-ebcc20034faa | foo-4 | ACTIVE || 977fd250-75d4-4da3-a37c-bc7649047151 | foo-2 | ACTIVE || a1182f44-7163-4ad9-89ed-36611f75bac7 | foo-5 | ACTIVE || a91951b3-ff4e-46a0-a5fd-20064f02afc9 | foo-3 | ACTIVE || f0a62c20-2304-4c8c-aaf5-f5bc9d385b5f | foo-1 | ACTIVE |+--------------------------------------+-------+--------+
To show which metrics are stored for the vm foo-1 one would use the following
command
This shows, the data is available with granularity 3600, 60 and 1 sec. The memory usage does
not change over the time, that's why the values don't change. Please
note, if you'd be asking for values with the granularity of 300,
the result will be empty
$ openstack metric measures show --start 2021-11-18T17:00:00 \
--stop 2021-11-18T17:05:00 \
--aggregation mean \
--granularity 300
b768ec46-5e49-4d9a-b00d-004f610c152d
Aggregation method 'mean' at granularity '300.0'for metric b768ec46-5e49-4d9a-b00d-004f610c152d does not exist (HTTP 404)
More info about the metric can be actually listed by using
That means, in this case, the aggregation methods one could use for querying
the metrics are just mean and rate:mean. Other methods could include min or max.
Alarming
Alarms can be retrieved by issuing
$ openstack alarm list
To create an alarm, for example based on disk.ephemeral.size, one would use something
like
The state here insufficient data states, the data gathered or
stored is not sufficient to compare against. There is also a state
reason given, in this case Not evaluated yet, which gives an explanation.
Another valid reason could be No datapoint for granularity 60.
Further debugging
On OpenStack installations deployed via Tripleo aka OSP Director, the log files are located
on the separate nodes under /var/log/containers/{service_name}/. The config files for
the services are stored under /var/lib/config-data/puppet-generated/<service_name>
and are mounted into the containers.
The RDO community is pleased to announce the general availability of the RDO build for OpenStack Xena for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Xena is the 24th release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
PLEASE NOTE: RDO Xena provides packages for CentOS Stream 8 only. Please use the Victoria release for CentOS Linux 8 which will reach End Of Life (EOL) on December 31st, 2021 (https://www.centos.org/centos-linux-eol/).
Interesting things in the Xena release include:
The python-oslo-limit package has been added to RDO. This is the limit enforcement library which assists with quota calculation. Its aim is to provide support for quota enforcement across all OpenStack services.
The glance-tempest-plugin package has been added to RDO. This package provides a set of functional tests to validate Glance using the Tempest framework.
TripleO has been moved to an independent release model (see section TripleO in the RDO Xena release).
RDO Xena will include packages for TripleO tested at OpenStack Xena GA time.
Those packages will not be updated during the entire Xena maintenance cycle.
RDO will not be able to included patches required to fix bugs in TripleO on RDO Xena.
The lifecycle for the non-TripleO packages will follow the code merged and tested in upstream stable/Xena branches.
There will not be any TripleO Xena container images built/pushed, so interested users will have to do their own container builds when deploying Xena.
You can find details about this on the RDO webpage
Contributors
During the Xena cycle, we saw the following new RDO contributors:
Chris Sibbitt
Gregory Thiemonge
Julia Kreger
Leif Madsen
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 41 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and redhat-website repositories:
Alan Bishop
Alan Pevec
Alex Schultz
Alfredo Moralejo
Amy Marrich (spotz)
Bogdan Dobrelya
Chandan Kumar
Chris Sibbitt
Damien Ciabrini
Dmitry Tantsur
Eric Harney
Gaël Chamoulaud
Giulio Fidente
Goutham Pacha Ravi
Gregory Thiemonge
Grzegorz Grasza
Harald Jensas
James Slagle
Javier Peña
Jiri Podivin
Joel Capitao
Jon Schlueter
Julia Kreger
Lee Yarwood
Leif Madsen
Luigi Toscano
Marios Andreou
Mark McClain
Martin Kopec
Mathieu Bultel
Matthias Runge
Michele Baldessari
Pranali Deore
Rabi Mishra
Riccardo Pittau
Sagi Shnaidman
Sławek Kapłoński
Steve Baker
Takashi Kajinami
Wes Hayutin
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Yoga.
Get Started
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on OFTC IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS and TripleO IRC channels (#centos, #centos-devel in Libera.Chat network, and #tripleo on OFTC), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and #tripleo on the OFTC IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
If an OpenStack server (Ironic or Nova) has an error, it shows up in a nested field. That field is hard to read in its normal layout, due to JSON formatting. Using jq to strip the formatting helps a bunch
The nested field is fault.details.
The -r option strips off the quotes.
[ayoung@ayoung-home scratch]$ openstack server show oracle-server-84-aarch64-vm-small -f json | jq -r '.fault | .details'
Traceback (most recent call last):
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/compute/manager.py", line 2437, in _build_and_run_instance
block_device_info=block_device_info)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/driver.py", line 3458, in spawn
block_device_info=block_device_info)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/driver.py", line 3831, in _create_image
fallback_from_host)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/driver.py", line 3922, in _create_and_inject_local_root
instance, size, fallback_from_host)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/driver.py", line 9243, in _try_fetch_image_cache
trusted_certs=instance.trusted_certs)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/imagebackend.py", line 275, in cache
*args, **kwargs)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/imagebackend.py", line 642, in create_image
self.verify_base_size(base, size)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/virt/libvirt/imagebackend.py", line 331, in verify_base_size
flavor_size=size, image_size=base_size)
nova.exception.FlavorDiskSmallerThanImage: Flavor's disk is too small for requested image. Flavor disk is 21474836480 bytes, image is 34359738368 bytes.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/compute/manager.py", line 2161, in _do_build_and_run_instance
filter_properties, request_spec)
File "/var/lib/kolla/venv/lib/python3.7/site-packages/nova/compute/manager.py", line 2525, in _build_and_run_instance
reason=e.format_message())
nova.exception.BuildAbortException: Build of instance 5281b93a-0c3c-4d38-965d-568d79abb530 aborted: Flavor's disk is too small for requested image. Flavor disk is 21474836480 bytes, image is 34359738368 bytes.
My team is running a small OpenStack cluster with reposnsibility for providing bare metal nodes via Ironic. Currently, we have a handful of nodes that are not usable. They show up as “Cleaning failed.” I’m learning how to debug this process.
Tools
The following ipmtool commands allow us to set the machine to PXE boot, remote power cycle the machine, and view what happens during the boot process.
Power stuff:
ipmitool -H $H -U $U -I lanplus -P $P chassis power status
ipmitool -H $H -U $U -I lanplus -P $P chassis power on
ipmitool -H $H -U $U -I lanplus -P $P chassis power off
ipmitool -H $H -U $U -I lanplus -P $P chassis power cycle
To look at the IPM power status (and confirm that IPMI is set up right for the nodes)
for node in `openstack baremetal node list -f json | jq -r '.[] | select(."Provisioning State"=="clean failed") | .UUID' ` ;
do
echo $node ;
METAL_IP=`openstack baremetal node show $node -f json | jq -r '.driver_info | .ipmi_address' ` ;
echo $METAL_IP ;
ipmitool -I lanplus -H $METAL_IP -L ADMINISTRATOR -U admin -R 12 -N 5 -P admin chassis power status ;
done
Yes, I did that all on one line, hence the semicolons.
A couple other one liners. This selects all active nodes and gives you their node id and ipmi IP address.
for node in `openstack baremetal node list -f json | jq -r '.[] | select(."Provisioning State"=="active") | .UUID' ` ; do echo $node ; openstack baremetal node show $node -f json | jq -r '.driver_info | .ipmi_address' ;done
And you can swap out active with other values. For example, if you want to see what nodes are in either error or clean failed states:
openstack baremetal node list -f json | jq -r '.[] | select(."Provisioning State"=="error" or ."Provisioning State"=="manageable") | .UUID'
Troubleshooting
PXE outside of openstack
If I want to ensure I can PXE boot, out side of the openstack operations, in one terminal, I can track the state in a console. I like to have this running in a dedicated terminal: open the SOL.
If you run the three commands I showed above, the Ironic server should be prepared for cleaning and will accept the PXE request. I can execute these one at a time and track the state in the conductor log. If I kick off a clean, eventually, I see entries like this in the conductor log (I’m removing the time stamps and request ids for readability):
ERROR ironic.conductor.task_manager [] Node 5411e7e8-8113-42d6-a966-8cacd1554039 moved to provision state "clean failed" from state "clean wait"; target provision state is "available"
INFO ironic.conductor.utils [] Successfully set node 5411e7e8-8113-42d6-a966-8cacd1554039 power state to power off by power off.
INFO ironic.drivers.modules.network.flat [] Removing ports from cleaning network for node 5411e7e8-8113-42d6-a966-8cacd1554039
INFO ironic.common.neutron [] Successfully removed node 5411e7e8-8113-42d6-a966-8cacd1554039 neutron ports.
Manual abort
And I can trigger this manually if a run is taking too long by running:
openstack baremetal node abort $UUID
Kick off clean process
The command to kick off the clean process is
openstack baremetal node provide $UUID
In the conductor log, that should show messages like this (again, edited for readability)
Node 5411e7e8-8113-42d6-a966-8cacd1554039 moved to provision state "cleaning" from state "manageable"; target provision state is "available"
Adding cleaning network to node 5411e7e8-8113-42d6-a966-8cacd1554039
For node 5411e7e8-8113-42d6-a966-8cacd1554039 in network de931fcc-32a0-468e-8691-ffcb43bf9f2e, successfully created ports (ironic ID: neutron ID): {'94306ff5-5cd4-4fdd-a33e-a0202c34d3d0': 'd9eeb64d-468d-4a9a-82a6-e70d54b73e62'}.
Successfully set node 5411e7e8-8113-42d6-a966-8cacd1554039 power state to power on by rebooting.
Node 5411e7e8-8113-42d6-a966-8cacd1554039 moved to provision state "clean wait" from state "cleaning"; target provision state is "available"
PXE during a clean
At this point, the most interesting thing is to see what is happening on the node. ipmiptool sol activate provides a running log. If you are lucky, the PXE process kicks off and a debian-based kernel should start booting. My company has a specific login set for the machines:
ls /var/log/
btmp ibacm.log opensm.0x9a039bfffead6720.log private
chrony lastlog opensm.0x9a039bfffead6721.log wtmp
No ironic log. Is this thing even on the network?
# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp1s0f0np0: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 98:03:9b:ad:67:20 brd ff:ff:ff:ff:ff:ff
3: enp1s0f1np1: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 98:03:9b:ad:67:21 brd ff:ff:ff:ff:ff:ff
4: enxda90910dd11e: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether da:90:91:0d:d1:1e brd ff:ff:ff:ff:ff:ff
Nope. Ok, lets get it on the network:
# dhclient
[ 486.508054] mlx5_core 0000:01:00.1 enp1s0f1np1: Link down
[ 486.537116] mlx5_core 0000:01:00.1 enp1s0f1np1: Link up
[ 489.371586] mlx5_core 0000:01:00.0 enp1s0f0np0: Link down
[ 489.394050] IPv6: ADDRCONF(NETDEV_CHANGE): enp1s0f1np1: link becomes ready
[ 489.400646] mlx5_core 0000:01:00.0 enp1s0f0np0: Link up
[ 489.406226] IPv6: ADDRCONF(NETDEV_CHANGE): enp1s0f0np0: link becomes ready
root@debian:~# [ 500.596626] sr 0:0:0:0: [sr0] CDROM not ready. Make sure there is a disc in the drive.
ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp1s0f0np0: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 98:03:9b:ad:67:20 brd ff:ff:ff:ff:ff:ff
inet 192.168.97.178/24 brd 192.168.97.255 scope global dynamic enp1s0f0np0
valid_lft 86386sec preferred_lft 86386sec
inet6 fe80::9a03:9bff:fead:6720/64 scope link
valid_lft forever preferred_lft forever
3: enp1s0f1np1: mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 98:03:9b:ad:67:21 brd ff:ff:ff:ff:ff:ff
inet6 fe80::9a03:9bff:fead:6721/64 scope link
valid_lft forever preferred_lft forever
4: enxda90910dd11e: mtu 1500 qdisc pfifo_fast state UNKNOWN group default qlen 1000
link/ether da:90:91:0d:d1:1e brd ff:ff:ff:ff:ff:ff
inet6 fe80::d890:91ff:fe0d:d11e/64 scope link
valid_lft forever preferred_lft forever
And…quite shortly thereafter in the conductor log:
Agent on node 5411e7e8-8113-42d6-a966-8cacd1554039 returned cleaning command success, moving to next clean step
Node 5411e7e8-8113-42d6-a966-8cacd1554039 moved to provision state "cleaning" from state "clean wait"; target provision state is "available"
Executing cleaning on node 5411e7e8-8113-42d6-a966-8cacd1554039, remaining steps: []
Successfully set node 5411e7e8-8113-42d6-a966-8cacd1554039 power state to power off by power off.
Removing ports from cleaning network for node 5411e7e8-8113-42d6-a966-8cacd1554039
Successfully removed node 5411e7e8-8113-42d6-a966-8cacd1554039 neutron ports.
Node 5411e7e8-8113-42d6-a966-8cacd1554039 cleaning complete
Node 5411e7e8-8113-42d6-a966-8cacd1554039 moved to provision state "available" from state "cleaning"; target provision state is "None"
Cause of Failure
So, in our case, the issue seems to be that the IPA image does not have dhcp enabled.
I’ve been a regular visitor to Stack Overflow and other Stack
Exchange sites over the years, and while I’ve mostly enjoyed the
experience, I’ve been frustrated by the lack of control I have over
what questions I see. I’m not really interested in looking at
questions that have already been closed, or that have a negative
score, but there’s no native facility for filtering questions like
this.
I finally spent the time learning just enough JavaScript to hurt
myself to put together a pair of scripts that let me present the
questions that way I want:
Because I wanted it to be obvious that the script was actually doing
something, hidden questions don’t just disappear; they fade out.
These behaviors (including the fading) can all be controlled
individually by a set of global variables at the top of the script.
sx-reorder questions
The sx-reorder-questions script will sort questions such that
anything that has an answer will be at the bottom, and questions that
have not yet been answered appear at the top.
Installation
If you are using the Tampermonkey extension, you should be able to
click on the links to the script earlier in this post and be taken
directly to the installation screen. If you’re not running
Tampermonkey, than either (a) install it, or (b) you’re on your own.
These scripts rely on the CSS classes and layout of the Stack Exchange
websites. If these change, the scripts will need updating. If you
notice that something no longer works as advertised, please feel free
to submit pull request with the necessary corrections!
At $JOB we maintain the configuration for our OpenShift clusters in a public git repository. Changes in the git repository are applied automatically using ArgoCD and Kustomize. This works great, but the public nature of the repository means we need to find a secure solution for managing secrets (such as passwords and other credentials necessary for authenticating to external services). In particular, we need a solution that permits our public repository to be the source of truth for our cluster configuration, without compromising our credentials.
Rejected options
We initially looked at including secrets directly in the repository through the use of the KSOPS plugin for Kustomize, which uses sops to encrypt secrets with GPG keys. There are some advantages to this arrangement:
It doesn’t require any backend service
It’s easy to control read access to secrets in the repository by encrypting them to different recipients.
There were some minor disadvantages:
We can’t install ArgoCD via the operator because we need a customized image that includes KSOPS, so we have to maintain our own ArgoCD image.
And there was one major problem:
Using GPG-encrypted secrets in a git repository makes it effectively impossible to recover from a key compromise.
One a private key is compromised, anyone with access to that key and the git repository will be able to decrypt data in historical commits, even if we re-encrypt all the data with a new key.
Because of these security implications we decided we would need a different solution (it’s worth noting here that Bitnami Sealed Secrets suffers from effectively the same problem).
The External Secrets project allows one to store secrets in an external secrets store, such as AWS SecretsManager, Hashicorp Vault, and others 1. The manifests that get pushed into your OpenShift cluster contain only pointers (called ExternalSecrets) to those secrets; the external secrets controller running on the cluster uses the information contained in the ExternalSecret in combination with stored credentials to fetch the secret from your chosen backend and realize the actual Secret resource. An external secret manifest referring to a secret named mysceret stored in AWS SecretsManager would look something like:
This model means that no encrypted data is ever stored in the git repository, which resolves the main problem we had with the solutions mentioned earlier.
External Secrets can be installed into your Kubernetes environment using Helm, or you can use helm template to generate manifests locally and apply them using Kustomize or some other tool (this is the route we took).
AWS SecretsManager Service
AWS SecretsManager is a service for storing and managing secrets and making them accessible via an API. Using SecretsManager we have very granular control over who can view or modify secrets; this allows us, for example, to create cluster-specific secret readers that can only read secrets intended for a specific cluster (e.g. preventing our development environment from accidentally using production secrets).
SecretsManager provides automatic versioning of secrets to prevent loss of data if you inadvertently change a secret while still requiring the old value.
We can create secrets through the AWS SecretsManager console, or we can use the AWS CLI, which looks something like:
Because we’re not storing actual secrets in the repository, we don’t need to worry about encrypting anything.
Because we’re not managing encrypted data, replacing secrets is much easier.
There’s a robust mechanism for controlling access to secrets.
This solution offers a separation of concern that simply wasn’t possible with the KSOPS model: someone can maintain secrets without having to know anything about Kubernetes manifests, and someone can work on the repository without needing to know any secrets.
Creating external secrets
In its simplest form, an ExternalSecret resource maps values from specific named secrets in the backend to keys in a Secret resource. For example, if we wanted to create a Secret in OpenShift with the username and password for an external service, we could create to separate secrets in SecretsManager. One for the username:
This instructs the External Secrets controller to create an Opaque secret named example-secret from data in AWS SecretsManager. The value of the username key will come from the secret named cluster/cluster1/example-secret-username, and similarly for password. The resulting Secret resource will look something like this:
In the previous example, we created two separate secrets in SecretsManager for storing a username and password. It might be more convenient if we could store both credentials in a single secret. Thanks to the templating support in External Secrets, we can do that!
Let’s redo the previous example, but instead of using two separate secrets, we’ll create a single secret named cluster/cluster1/example-secret in which the secret value is a JSON document containing both the username and password:
…which makes it easier to write JSON without missing a quote, closing bracket, etc.
We can extract these values into the appropriate keys by adding a template section to our ExternalSecret, and using the JSON.parse template function, like this:
Notice that in addition to the values created in the template section, the Secret also contains any keys defined in the data section of the ExternalSecret.
Templating can also be used to override the secret type if you want something other than Opaque, add metadata, and otherwise influence the generated Secret.
E.g. Azure Key Vault, Google Secret Manager, Alibaba Cloud KMS Secret Manager, Akeyless ↩︎
Red Hat’s OpenShift Data Foundation (formerly “OpenShift
Container Storage”, or “OCS”) allows you to either (a) automatically
set up a Ceph cluster as an application running on your OpenShift
cluster, or (b) connect your OpenShift cluster to an externally
managed Ceph cluster. While setting up Ceph as an OpenShift
application is a relatively polished experienced, connecting to an
external cluster still has some rough edges.
NB I am not a Ceph expert. If you read this and think I’ve made a
mistake with respect to permissions or anything else, please feel free
to leave a comment and I will update the article as necessary. In
particular, I think it may be possible to further restrict the mgr
permissions shown in this article and I’m interested in feedback on
that topic.
Installing OCS
Regardless of which option you choose, you start by installing the
“OpenShift Container Storage” operator (the name change apparently
hasn’t made it to the Operator Hub yet). When you select “external
mode”, you will be given the opportunity to download a Python script
that you are expected to run on your Ceph cluster. This script will
create some Ceph authentication principals and will emit a block of
JSON data that gets pasted into the OpenShift UI to configure the
external StorageCluster resource.
The script has a single required option, --rbd-data-pool-name, that
you use to provide the name of an existing pool. If you run the script
with only that option, it will create the following ceph principals
and associated capabilities:
If you specify --rgw-endpoint, the script will create a RGW user
named rgw-admin-ops-userwith administrative access to the default
RGW pool.
So what’s the problem?
The above principals and permissions are fine if you’ve created an
external Ceph cluster explicitly for the purpose of supporting a
single OpenShift cluster.
In an environment where a single Ceph cluster is providing storage to
multiple OpenShift clusters, and especially in an environment where
administration of the Ceph and OpenShift environments are managed by
different groups, the process, principals, and permissions create a
number of problems.
The first and foremost is that the script provided by OCS both (a)
gathers information about the Ceph environment, and (b) makes changes
to that environment. If you are installing OCS on OpenShift and want
to connect to a Ceph cluster over which you do not have administrative
control, you may find yourself stymied when the storage administrators
refuse to run your random Python script on the Ceph cluster.
Ideally, the script would be read-only, and instead of making
changes to the Ceph cluster it would only validate the cluster
configuration, and inform the administrator of what changes were
necessary. There should be complete documentation that describes the
necessary configuration scripts so that a Ceph cluster can be
configured correctly without running any script, and OCS should
provide something more granular than “drop a blob of JSON here” for
providing the necessary configuration to OpenShift.
The second major problem is that while the script creates several
principals, it only allows you to set the name of one of them. The
script has a --run-as-user option, which at first sounds promising,
but ultimately is of questionable use: it only allows you set the Ceph
principal used for cluster health checks.
There is no provision in the script to create separate principals for
each OpenShift cluster.
Lastly, the permissions granted to the principals are too broad. For
example, the csi-rbd-node principal has access to all RBD pools on
the cluster.
How can we work around it?
If you would like to deploy OCS in an environment where the default
behavior of the configuration script is inappropriate you can work
around this problem by:
Manually generating the necessary principals (with more appropriate
permissions), and
Manually generating the JSON data for input into OCS
Create the storage
I’ve adopted the following conventions for naming storage pools and
filesystems:
All resources are prefixed with the name of the cluster (represented
here by ${clustername}).
The RBD pool is named ${clustername}-rbd. I create it like this:
ceph osd pool create ${clustername}-rbd
ceph osd pool application enable ${clustername}-rbd rbd
The CephFS filesystem (if required) is named
${clustername}-fs, and I create it like this:
ceph fs volume create ${clustername}-fs
In addition to the filesystem, this creates two pools:
cephfs.${clustername}-fs.meta
cephfs.${clustername}-fs.data
Creating the principals
Assuming that you have followed the same conventions and have an RBD
pool named ${clustername}-rbd and a CephFS filesystem named
${clustername}-fs, the following set of ceph auth add commands
should create an appropriate set of principals (with access limited to
just those resources that belong to the named cluster):
Note that I’ve excluded the RGW permissions here; in our OpenShift
environments, we typically rely on the object storage interface
provided by Noobaa so I haven’t spent time investigating
permissions on the RGW side.
Create the JSON
The final step is to create the JSON blob that you paste into the OCS
installation UI. I use the following script which calls ceph -s,
ceph mon dump, and ceph auth get-key to get the necessary
information from the cluster:
If you’d prefer a strictly manual process, you can fill in the
necessary values yourself. The JSON produced by the above script
looks like the following, which is invalid JSON because I’ve use
inline comments to mark all the values which you would need to
provide:
[
{
"name": "rook-ceph-mon-endpoints",
"kind": "ConfigMap",
"data": {
# The format is <mon_name>=<mon_endpoint>, and you only need to
# provide a single mon address.
"data": "ceph0=192.168.122.140:6789",
"maxMonId": "0",
"mapping": "{}"
}
},
{
"name": "rook-ceph-mon",
"kind": "Secret",
"data": {
# Fill in the fsid of your Ceph cluster.
"fsid": "c9c32c73-dac4-4cc9-8baa-d73b96c135f4",
# Do **not** fill in these values, they are unnecessary. OCS
# does not require admin access to your Ceph cluster.
"admin-secret": "admin-secret",
"mon-secret": "mon-secret"
}
},
{
"name": "rook-ceph-operator-creds",
"kind": "Secret",
"data": {
# Fill in the name and key for your healthchecker principal.
# Note that here, unlike elsewhere in this JSON, you must
# provide the "client." prefix to the principal name.
"userID": "client.healthchecker-mycluster",
"userKey": "<key>"
}
},
{
"name": "ceph-rbd",
"kind": "StorageClass",
"data": {
# Fill in the name of your RBD pool.
"pool": "mycluster-rbd"
}
},
{
"name": "monitoring-endpoint",
"kind": "CephCluster",
"data": {
# Fill in the address and port of the Ceph cluster prometheus
# endpoint.
"MonitoringEndpoint": "192.168.122.140",
"MonitoringPort": "9283"
}
},
{
"name": "rook-csi-rbd-node",
"kind": "Secret",
"data": {
# Fill in the name and key of the csi-rbd-node principal.
"userID": "csi-rbd-node-mycluster",
"userKey": "<key>"
}
},
{
"name": "rook-csi-rbd-provisioner",
"kind": "Secret",
"data": {
# Fill in the name and key of your csi-rbd-provisioner
# principal.
"userID": "csi-rbd-provisioner-mycluster",
"userKey": "<key>"
}
},
{
"name": "rook-csi-cephfs-provisioner",
"kind": "Secret",
"data": {
# Fill in the name and key of your csi-cephfs-provisioner
# principal.
"adminID": "csi-cephfs-provisioner-mycluster",
"adminKey": "<key>"
}
},
{
"name": "rook-csi-cephfs-node",
"kind": "Secret",
"data": {
# Fill in the name and key of your csi-cephfs-node principal.
"adminID": "csi-cephfs-node-mycluster",
"adminKey": "<key>"
}
},
{
"name": "cephfs",
"kind": "StorageClass",
"data": {
# Fill in the name of your CephFS filesystem and the name of the
# associated data pool.
"fsName": "mycluster-fs",
"pool": "cephfs.mycluster-fs.data"
}
}
]
Associated Bugs
I’ve opened several bug reports to see about adressing some of these
issues:
#1996833
“ceph-external-cluster-details-exporter.py should have a read-only
mode”
#1996830 “OCS
external mode should allow specifying names for all Ceph auth
principals”
#1996829
“Permissions assigned to ceph auth principals when using external
storage are too broad”
OS Migrate is a toolbox
for content migration (workloads and more) between
OpenStack clouds. Let’s dive into why
you’d use it, some of its most notable features, and a bit of how it
works.
The Why
Why move cloud content between OpenStacks? Imagine these situations:
Old cloud hardware is obsolete, you’re buying new. A new green field
deployment will be easier than gradual replacement of hardware in
the original cloud.
You want to make fundamental changes to your OpenStack deployment,
that would be difficult or risky to perform on a cloud which is
already providing service to users.
You want to upgrade to a new release of OpenStack, but you want to
cut down on associated cloud-wide risk, or you can’t schedule
cloud-wide control plane downtime.
You want to upgrade to a new release of OpenStack, but the cloud
users should be given a choice when to stop using the old release
and start using the new.
A combination of the above.
In such situations, running (at least) two clouds in parallel for a
period of time is often the preferable path. And when you run parallel
clouds, perhaps with the intention of decomissioning some of them
eventually, a tool may come in handy to copy/migrate the content that
users have created (virtual networks, routers, security groups,
machines, block storage, images etc.) from one cloud to another. This
is what OS Migrate is for.
The Pitch
Now we know OS Migrate copies/moves content from one OpenStack to
another. But there is more to say. Some of the design decisions that
went into OS Migrate should make it a tool of choice:
Uses standard OpenStack APIs. You don’t need to install any
plugins into your clouds before using OS Migrate, and OS Migrate
does not need access to the backends of your cloud (databases etc.).
Runnable with tenant privileges. For moving tenant-owned
content, OS Migrate only needs tenant credentials (not
administrative credentials). This naturally reduces risks associated
with the migration.
If desired, cloud tenants can even use OS Migrate on their
own. Cloud admins do not necessarily need to get involved.
Admin credentials are only needed when the content being migrated
requires admin privileges to be created (e.g. public Glance images).
Transparent. The metadata of exported content is in
human-readable YAML files. You can inspect what has been exported
from the source cloud, and tweak it if necessary, before executing
the import into the destination cloud.
Stateless. There is no database in OS Migrate that could get out
of sync with reality. The source of migration information are the
human readable YAML files. ID-to-ID mappings are not kept,
entry-point resources are referred to by names.
Idempotent. In case of an issue, fix the root cause and re-run,
be it export or import. OS Migrate has mechanisms against duplicit
exports and duplicit imports.
Cherry-pickable. There’s no need to migrate all content with OS
Migrate. Only migrate some tenants, or further scope to some of
their resource types, or further limit the resource type
exports/imports by a list of resource names or regular expression
patterns. Use as much or as little of OS Migrate as you need.
Implemented as an Ansible collection. When learning to work with
OS Migrate, most importantly you’ll be learning to work with
Ansible, an automation tool used across the IT industry. If you
already know Ansible, you’ll feel right at home with OS Migrate.
The How
If you want to use OS Migrate, the best thing I can do here is point
towards the OS Migrate User
Documentation. If
you just want to get a glimpse for now, read on.
As OS Migrate is an Ansible collection, the main mode of use is
setting Ansible variables and running playbooks shipped with the
collection.
Should the default playbooks not fit a particular use case, a
technically savvy user could also utilize the collection’s roles and
modules as building blocks to craft their own playbooks. However, as
i’ve wrote above in the point about cherry-picking features, we’ve
tried to make the default playbooks quite generically usable.
In OS Migrate we differentiate between two main migration types with
respect to what resources we are migrating: pre-workload migration,
and workload migration.
Pre-workload migration
Pre-workload migration focuses on content/resources that can be copied
to the destination cloud without affecting workloads in the source
cloud. It can be typically done with little timing pressure, ahead of
time before migrating workloads. This includes resources like tenant
networks, subnets, routers, images, security groups etc.
The content is serialized as editable YAML files to the Migrator host
(the machine running the Ansible playbooks), and then resources are
created in the destination according to the YAML serializations.
Workload migration
Workload migration focuses on copying VMs and their attached Cinder
volumes, and on creating floating IPs for VMs in the destination
cloud. The VM migration between clouds is a “cold” migration. VMs
first need to be stopped and then they are copied.
With regards to the boot disk of the VM, we support two options:
either the destination VM’s boot disk is created from a Glance image,
or the source VM’s boot disk snapshot is copied into the destination
cloud as a Cinder volume and the destination VM is created as
boot-from-volume. There is a migration
parameter
controlling this behavior on a per-VM basis. Additional Cinder volumes
attached to the source VM are copied.
The data path for VMs and volumes is slightly different than in the
pre-workload migration. Only metadata gets exported onto the Migrator
host. For moving the binary data, special VMs called conversion
hosts are deployed, one in the source and one in the
destination. This is done for performance reasons, to allow the VMs’
and volumes’ binary data to travel directly from cloud to cloud
without going through the (perhaps external) Migrator host as an
intermediary.
The Pointers
Now that we have an overview of OS Migrate, let’s finish with some
links where more info can be found:
The RDO community is pleased to announce the general availability of the RDO build for OpenStack Wallaby for RPM-based distributions, CentOS Stream and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Wallaby is the 23rd release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Stream and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
PLEASE NOTE: RDO Wallaby provides packages for CentOS Stream 8 and Python 3 only. Please use the Victoria release for CentOS8. For CentOS7 and python 2.7, please use the Train release.
Interesting things in the Wallaby release include:
With the Victoria release, source tarballs are validated using the upstream GPG signature. This certifies that the source is identical to what is released upstream and ensures the integrity of the packaged source code.
With the Victoria release, openvswitch/ovn are not shipped as part of RDO. Instead RDO relies on builds from the CentOS NFV SIG.
Some new packages have been added to RDO during the Victoria release:
RBAC supported added in multiple projects including Designate, Glance, Horizon, Ironic, and Octavia
Glance added support for distributed image import
Ironic added deployment and cleaning enhancements including UEFI Partition Image handling, NVMe Secure Erase, per-instance deployment driver interface overrides, deploy time “deploy_steps”, and file injection.
Kuryr added nested mode with node VMs running in multiple subnets is now available. To use that functionality a new option [pod_vif_nested]worker_nodes_subnets is introduced accepting multiple Subnet IDs.
Manila added the ability for Operators to now set maximum and minimum share sizes as extra specifications on share types.
Neutron added a new subnet type network:routed is now available. IPs on this subnet type can be advertised with BGP over a provider network.
TripleO moved network and network port creation out of the Heat stack and into the baremetal provisioning workflow.
During the Wallaby cycle, we saw the following new RDO contributors:
Adriano Petrich
Ananya Banerjee
Artom Lifshitz
Attila Fazekas
Brian Haley
David J Peacock
Jason Joyce
Jeremy Freudberg
Jiri Podivin
Martin Kopec
Waleed Mousa
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 58 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and redhat-website repositories:
Adriano Petrich
Alex Schultz
Alfredo Moralejo
Amol Kahat
Amy Marrich
Ananya Banerjee
Artom Lifshitz
Arx Cruz
Attila Fazekas
Bhagyashri Shewale
Brian Haley
Cédric Jeanneret
Chandan Kumar
Daniel Pawlik
David J Peacock
Dmitry Tantsur
Emilien Macchi
Eric Harney
Fabien Boucher
Gabriele Cerami
Gael Chamoulaud
Grzegorz Grasza
Harald Jensas
Jason Joyce
Javier Pena
Jeremy Freudberg
Jiri Podivin
Joel Capitao
Kevin Carter
Luigi Toscano
Marc Dequenes
Marios Andreou
Martin Kopec
Mathieu Bultel
Matthias Runge
Mike Turek
Nicolas Hicher
Pete Zaitcev
Pooja Jadhav
Rabi Mishra
Riccardo Pittau
Roman Gorshunov
Ronelle Landy
Sagi Shnaidman
Sandeep Yadav
Slawek Kaplonski
Sorin Sbarnea
Steve Baker
Takashi Kajinami
Tristan Cacqueray
Waleed Mousa
Wes Hayutin
Yatin Karel
The Next Release Cycle
At the end of one release, focus shifts immediately to the next release i.e Xena.
Get Started
There are three ways to get started with RDO.
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
For a production deployment of RDO, use TripleO and you’ll be running a production cloud in short order.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help
The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on Freenode IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS and TripleO IRC channels (#centos, #centos-devel, and #tripleo on irc.freenode.net), however we have a more focused audience within the RDO venues.
Get Involved
To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and #tripleo on the Freenode IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
In this post, we’ll walk through the process of getting virtual
machines on two different hosts to communicate over an overlay network
created using the support for VXLAN in Open vSwitch (or OVS).
The test environment
For this post, I’ll be working with two systems:
node0.ovs.virt at address 192.168.122.107
node1.ovs.virt at address 192.168.122.174
These hosts are running CentOS 8, although once we get past the
package installs the instructions will be similar for other
distributions.
While reading through this post, remember that unless otherwise
specified we’re going to be running the indicated commands on both
hosts.
Install packages
Before we can get started configuring things we’ll need to install OVS
and libvirt. While libvirt is included with the base CentOS
distribution, for OVS we’ll need to add both the EPEL repository
as well as a recent CentOS OpenStack repository (OVS is included
in the CentOS OpenStack repositories because it is required by
OpenStack’s networking service):
With all the prerequisites out of the way we can finally start working
with Open vSwitch. Our first task is to create the OVS bridge that
will host our VXLAN tunnels. To create a bridge named br0, we run:
ovs-vsctl add-br br0
We can inspect the OVS configuration by running ovs-vsctl show,
which should output something like:
Up until this point we’ve been running identical commands on both
node0 and node1. In order to create our VXLAN tunnels, we need to
provide a remote endpoint for the VXLAN connection, which is going to
be “the other host”. On node0, we run:
58451994-e0d1-4bf1-8f91-7253ddf4c016
Bridge br0
Port br0
Interface br0
type: internal
Port vx_node0
Interface vx_node0
type: vxlan
options: {remote_ip="192.168.122.107"}
ovs_version: "2.15.1"
At this point, we have a functional overlay network: anything attached
to br0 on either system will appear to share the same layer 2
network. Let’s take advantage of this to connect a pair of virtual
machines.
Create virtual machines
Download a base image
We’ll need a base image for our virtual machines. I’m going to use the
CentOS 8 Stream image, which we can download to our storage directory
like this:
This creates a 10GB “copy-on-write” disk that uses
centos-8-stream.qcow2 as a backing store. That means that reads will
generally come from the centos-8-stream.qcow2 image, but writes will
be stored in the new image. This makes it easy for us to quickly
create multiple virtual machines from the same base image.
On node1 we would run a similar command, although here we’re naming
the virtual machine vm1.0:
On node0, get the address of the new virtual machine on the default
network using the virsh domifaddr command:
[root@node0 ~]# virsh domifaddr vm0.0
Name MAC address Protocol Address
-------------------------------------------------------------------------------
vnet2 52:54:00:21:6e:4f ipv4 192.168.124.83/24
Connect to the vm using ssh:
[root@node0 ~]# ssh 192.168.124.83
root@192.168.124.83's password:
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Sat Apr 17 14:08:17 2021 from 192.168.124.1
[root@localhost ~]#
(Recall that the root password is secret.)
Configure interface eth1 with an address. For this post, we’ll use
the 10.0.0.0/24 range for our overlay network. To assign this vm the
address 10.0.0.10, we can run:
ip addr add 10.0.0.10/24 dev eth1
ip link set eth1 up
Configure networking for vm1.0
We need to repeat the process for vm1.0 on node1:
[root@node1 ~]# virsh domifaddr vm1.0
Name MAC address Protocol Address
-------------------------------------------------------------------------------
vnet0 52:54:00:e9:6e:43 ipv4 192.168.124.69/24
Connect to the vm using ssh:
[root@node0 ~]# ssh 192.168.124.69
root@192.168.124.69's password:
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Sat Apr 17 14:08:17 2021 from 192.168.124.1
[root@localhost ~]#
We’ll use address 10.0.0.11 for this system:
ip addr add 10.0.0.11/24 dev eth1
ip link set eth1 up
Verify connectivity
At this point, our setup is complete. On vm0.0, we can connect to
vm1.1 over the overlay network. For example, we can ping the remote
host:
[root@localhost ~]# ping -c2 10.0.0.11
PING 10.0.0.11 (10.0.0.11) 56(84) bytes of data.
64 bytes from 10.0.0.11: icmp_seq=1 ttl=64 time=1.79 ms
64 bytes from 10.0.0.11: icmp_seq=2 ttl=64 time=0.719 ms
--- 10.0.0.11 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 0.719/1.252/1.785/0.533 ms
Using tcpdump, we can verify that these connections are going over
the overlay network. Let’s watch for VXLAN traffic on node1 by
running the following command (VXLAN is a UDP protocol running on port
4789)
tcpdump -i eth0 -n port 4789
When we run ping -c2 10.0.0.11 on vm0.0, we see the following:
14:23:50.312574 IP 192.168.122.107.52595 > 192.168.122.174.vxlan: VXLAN, flags [I] (0x08), vni 0
IP 10.0.0.10 > 10.0.0.11: ICMP echo request, id 4915, seq 1, length 64
14:23:50.314896 IP 192.168.122.174.59510 > 192.168.122.107.vxlan: VXLAN, flags [I] (0x08), vni 0
IP 10.0.0.11 > 10.0.0.10: ICMP echo reply, id 4915, seq 1, length 64
14:23:51.314080 IP 192.168.122.107.52595 > 192.168.122.174.vxlan: VXLAN, flags [I] (0x08), vni 0
IP 10.0.0.10 > 10.0.0.11: ICMP echo request, id 4915, seq 2, length 64
14:23:51.314259 IP 192.168.122.174.59510 > 192.168.122.107.vxlan: VXLAN, flags [I] (0x08), vni 0
IP 10.0.0.11 > 10.0.0.10: ICMP echo reply, id 4915, seq 2, length 64
In the output above, we see that each packet in the transaction
results in two lines of output from tcpdump:
14:23:50.312574 IP 192.168.122.107.52595 > 192.168.122.174.vxlan: VXLAN, flags [I] (0x08), vni 0
IP 10.0.0.10 > 10.0.0.11: ICMP echo request, id 4915, seq 1, length 64
The first line shows the contents of the VXLAN packet, while the
second lines shows the data that was encapsulated in the VXLAN packet.
That’s all folks
We’ve achieved our goal: we have two virtual machines on two different
hosts communicating over a VXLAN overlay network. If you were to do
this “for real”, you would probably want to make a number of changes:
for example, the network configuration we’ve applied in many cases
will not persist across a reboot; handling persistent network
configuration is still very distribution dependent, so I’ve left it
out of this post.
collectd itself is intended as lightweight collecting agent for metrics
and events. In larger infrastructure, the data is sent over the network
to a central point, where data is stored and processed further.
This introduces a potential issue: what happens, if the remote endpoint
to write data to is not available. The traditional network plugin uses
UDP, which is by definition unreliable.
Collectd has a queue of values to be written to an output plugin, such
was write_http or amqp1. At the time, when metrics should be
written, collectd iterates on that queue and tries to write this data
to the endpoint. If writing was successful, the data is removed from
the queue. The little word if also hints, there is a chance that data
doesn't get removed. The question is: what happens, or what should be
done?
There is no easy answer to this. Some people tend to ignore missed
metrics, some don't. The way to address this is to cap the queue at a
given length and to remove oldest data when new comes in. The parameters
are WriteQueueLimitHigh and WriteQueueLimitLow. If they are unset,
the queue is not limited and will grow until memory is out. For
predictability reasons, you should set these two values to the same
number. To get the right value for this parameter, it would require a
bit of experimentation. If values are dropped, one would see that in
the log file.
When collectd is configured as part of Red Hat OpenStack Platform, the
following config snippet can be used:
Another parameter can be used to limit explicitly the queue length in
case the amqp1 plugin is used for sending out data: the SendQueueLimit
parameter, which is used for the same purpose, but can differ from the
global WriteQueueLimitHigh and WriteQueueLimitLow.
In almost all cases, the issue of collectd using much memory could be
tracked down to a write endpoint not being available, dropping data
occasionally, etc.
Kustomize is a tool for assembling Kubernetes manifests from a
collection of files. We’re making extensive use of Kustomize in the
operate-first project. In order to keep secrets stored in our
configuration repositories, we’re using the KSOPS plugin, which
enables Kustomize to use sops to encrypt/files using GPG.
In this post, I’d like to walk through the steps necessary to get
everything up and running.
Set up GPG
We encrypt files using GPG, so the first step is making sure that you
have a GPG keypair and that your public key is published where other
people can find it.
Install GPG
GPG will be pre-installed on most Linux distributions. You can check
if it’s installed by running e.g. gpg --version. If it’s not
installed, you will need to figure out how to install it for your
operating system.
Create a key
Run the following command to create a new GPG keypair:
gpg --full-generate-key
This will step you through a series of prompts. First, select a key
type. You can just press <RETURN> for the default:
gpg (GnuPG) 2.2.25; Copyright (C) 2020 Free Software Foundation, Inc.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Please select what kind of key you want:
(1) RSA and RSA (default)
(2) DSA and Elgamal
(3) DSA (sign only)
(4) RSA (sign only)
(14) Existing key from card
Your selection?
Next, select a key size. The default is fine:
RSA keys may be between 1024 and 4096 bits long.
What keysize do you want? (3072)
Requested keysize is 3072 bits
You will next need to select an expiration date for your key. The
default is “key does not expire”, which is a fine choice for our
purposes. If you’re interested in understanding this value in more
detail, the following articles are worth reading:
Setting an expiration date will require that you periodically update
the expiration date (or generate a new key).
Please specify how long the key should be valid.
0 = key does not expire
<n> = key expires in n days
<n>w = key expires in n weeks
<n>m = key expires in n months
<n>y = key expires in n years
Key is valid for? (0)
Key does not expire at all
Is this correct? (y/N) y
Now you will need to enter your identity, which consists of your name,
your email address, and a comment (which is generally left blank).
Note that you’ll need to enter o for okay to continue from this
prompt.
GnuPG needs to construct a user ID to identify your key.
Real name: Your Name
Email address: you@example.com
Comment:
You selected this USER-ID:
"Your Name <you@example.com>"
Change (N)ame, (C)omment, (E)mail or (O)kay/(Q)uit? o
Lastly, you need to enter a password. In most environments, GPG will
open a new window asking you for a passphrase. After you’ve entered and
confirmed the passphrase, you should see your key information on the
console:
gpg: key 02E34E3304C8ADEB marked as ultimately trusted
gpg: revocation certificate stored as '/home/lars/tmp/gpgtmp/openpgp-revocs.d/9A4EB5B1F34B3041572937C002E34E3304C8ADEB.rev'
public and secret key created and signed.
pub rsa3072 2021-03-11 [SC]
9A4EB5B1F34B3041572937C002E34E3304C8ADEB
uid Your Name <you@example.com>
sub rsa3072 2021-03-11 [E]
Publish your key
You need to publish your GPG key so that others can find it. You’ll
need your key id, which you can get by running gpg -k --fingerprint
like this (using your email address rather than mine):
$ gpg -k --fingerprint lars@oddbit.com
The output will look like the following:
pub rsa2048/0x362D63A80853D4CF 2013-06-21 [SC]
Key fingerprint = 3E70 A502 BB52 55B6 BB8E 86BE 362D 63A8 0853 D4CF
uid [ultimate] Lars Kellogg-Stedman <lars@oddbit.com>
uid [ultimate] keybase.io/larsks <larsks@keybase.io>
sub rsa2048/0x042DF6CF74E4B84C 2013-06-21 [S] [expires: 2023-07-01]
sub rsa2048/0x426D9382DFD6A7A9 2013-06-21 [E]
sub rsa2048/0xEE1A8B9F9369CC85 2013-06-21 [A]
Look for the Key fingerprint line, you want the value after the =.
Use this to publish your key to keys.openpgp.org:
In this section, we’ll get all the necessary tools installed on your
system in order to interact with a repository using Kustomize and
KSOPS.
Install Kustomize
Pre-compiled binaries of Kustomize are published on
GitHub. To install the command, navigate to the current
release (v4.0.5 as of this writing) and download the appropriate
tarball for your system. E.g, for an x86-64 Linux environment, you
would grab kustomize_v4.0.5_linux_amd64.tar.gz.
The tarball contains a single file. You need to extract this file and
place it somwhere in your $PATH. For example, if you use your
$HOME/bin directory, you could run:
tar -C ~/bin -xf kustomize_v4.0.5_linux_amd64.tar.gz
Or to install into /usr/local/bin:
sudo tar -C /usr/local/bin -xf kustomize_v4.0.5_linux_amd64.tar.gz
Run kustomize with no arguments to verify the command has been
installed correctly.
Install sops
The KSOPS plugin relies on the sops command, so we need to install
that first. Binary releases are published on GitHub, and the current
release is v3.6.1.
Instead of a tarball, the project publishes the raw binary as well as
packages for a couple of different Linux distributions. For
consistency with the rest of this post we’re going to grab the raw
binary. We can install that into $HOME/bin like this:
KSOPS is a Kustomize plugin. The kustomize command looks for plugins
in subdirectories of $HOME/.config/kustomize/plugin. Directories are
named after an API and plugin name. In the case of KSOPS, kustomize
will be looking for a plugin named ksops in the
$HOME/.config/kustomize/plugin/viaduct.ai/v1/ksops/ directory.
The current release of KSOPS is v2.4.0, which is published as a
tarball. We’ll start by downloading
ksops_2.4.0_Linux_x86_64.tar.gz, which contains the following
files:
LICENSE
README.md
ksops
To extract the ksops command to $HOME/bin, you can run:
mkdir -p ~/.config/kustomize/plugin/viaduct.ai/v1/ksops/
tar -C ~/.config/kustomize/plugin/viaduct.ai/v1/ksops -xf ksops_2.4.0_Linux_x86_64.tar.gz ksops
Test it out
Let’s create a simple Kustomize project to make sure everything is
installed and functioning.
Start by creating a new directory and changing into it:
mkdir kustomize-test
cd kustomize-test
Create a kustomization.yaml file that looks like this:
generators:
- secret-generator.yaml
Put the following content in secret-generator.yaml:
This instructs Kustomize to use the KSOPS plugin to generate content
from the file example-secret.enc.yaml.
Configure sops to use your GPG key by default by creating a
.sops.yaml (note the leading dot) similar to the following (you’ll
need to put your GPG key fingerprint in the right place):
The encrypted_regex line tells sops which attributes in your YAML
files should be encrypted. The pgp line is a (comma delimited) list
of keys to which data will be encrypted.
Now, edit the file example-secret.enc.yaml using the sops command.
Run:
sops example-secret.enc.yaml
This will open up an editor with some default content. Replace the
content with the following:
apiVersion: v1
kind: Secret
metadata:
name: example-secret
type: Opaque
stringData:
message: this is a test
Save the file and exit your editor. Now examine the file; you will see
that it contains a mix of encrypted and unencrypted content. When
encrypted with my private key, it looks like this:
I sometimes find myself writing articles or documentation about
git, so I put together a couple of terrible hacks for generating
reproducible histories and pretty graphs of those histories.
git synth
The git synth command reads a YAML description of a
repository and executes the necessary commands to reproduce that
history. It allows you set the name and email address of the author
and committer as well as static date, so you every time you generate
the repository you can identical commit ids.
git dot
The git dot command generates a representation of a repository
history in the dot language, and uses Graphviz to render those
into diagrams.
Putting it together
For example, the following history specification:
<!-- include examplerepo.yml -->
When applied with git synth:
$ git synth -r examplerepo examplerepo.yml
Will generate the following repository:
$ git -C examplerepo log --graph --all --decorate --oneline
* 28f7b38 (HEAD -> master) H
| * 93e1d18 (topic2) G
| * 3ef811d F
| * 973437c (topic1) E
| * 2c0bd1c D
|/
* cabdedf C
* a5cbd99 B
* d98f949 A
To produce the following dot description of the history:
<!-- include examplerepo.dot -->
Running that through the dot utility (dot -Tsvg -o repo.svg repo.dot) results in the following diagram:
<!-- include examplerepo.dot -->
Where are these wonders?
Both tools live in my git-snippets repository, which is a motley
collection of shells scripts, python programs, and other utilities for
interacting with git.
It’s all undocumented and uninstallable, but if there’s interest in
either of these tools I can probably find the time to polish them up a
bit.
I sometimes find myself writing articles or documentation about
git, so I put together a couple of terrible hacks for generating
reproducible histories and pretty graphs of those histories.
git synth
The git synth command reads a YAML description of a
repository and executes the necessary commands to reproduce that
history. It allows you set the name and email address of the author
and committer as well as static date, so you every time you generate
the repository you can identical commit ids.
git dot
The git dot command generates a representation of a repository
history in the dot language, and uses Graphviz to render those
into diagrams.
Putting it together
For example, the following history specification:
- set:
date: "2021-01-01"
name: Fake Person
email: fake@example.com
- branch:
name: master
actions:
- commit:
message: A
- commit:
message: B
- commit:
message: C
- branch:
name: topic1
actions:
- commit:
message: D
- commit:
message: E
- branch:
name: topic2
actions:
- commit:
message: F
- commit:
message: G
- commit:
message: H
When applied with git synth:
$ git synth -r examplerepo examplerepo.yml
Will generate the following repository:
$ git -C examplerepo log --graph --all --decorate --oneline
* 28f7b38 (HEAD -> master) H
| * 93e1d18 (topic2) G
| * 3ef811d F
| * 973437c (topic1) E
| * 2c0bd1c D
|/
* cabdedf C
* a5cbd99 B
* d98f949 A
Running that through the dot utility (dot -Tsvg -o repo.svg repo.dot) results in the following diagram:
Where are these wonders?
Both tools live in my git-snippets repository, which is a motley
collection of shells scripts, python programs, and other utilities for
interacting with git.
It’s all undocumented and uninstallable, but if there’s interest in
either of these tools I can probably find the time to polish them up a
bit.
This is just a note that I’ve substantially changed how the post
sources are organized. I’ve tried to ensure that I preserve all the
existing links, but if you spot something missing please feel free to
leave a comment on this post.
This is just a note that I’ve substantially changed how the post sources are organized. I’ve tried to ensure that I preserve all the existing links, but if you spot something missing please feel free to leave a comment on this post.
While working on a pull request I will make liberal use of git
rebase to clean up a series of commits: squashing typos,
re-ordering changes for logical clarity, and so forth. But there are
some times when all I want to do is change a commit message somewhere
down the stack, and I was wondering if I had any options for doing
that without reaching for git rebase.
It turns out the answer is “yes”, as long as you have a linear
history.
Let’s assume we have a git history that looks like this:
commit 2951ec3f54205580979d63614ef2751b61102c5d
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Add detailed, high quality documentation
commit 38f6fe61ffd444f601ac01ecafcd524487c83394
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Fixed bug that would erroneously call rm -rf
commit 51963667037ceb79aff8c772a009a5fbe4b8d7d9
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
A very interesting change
commit 4be8115640821df1565c421d8ed848bad34666e5
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
The beginning of time
Mucking about with objects
We would like to modify the message on commit 519636.
We start by extracting the commit object for that commit using git cat-file:
$ git cat-file -p 519636
tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904
parent 4be8115640821df1565c421d8ed848bad34666e5
author Alice User <alice@example.com> 978325200 -0500
committer Alice User <alice@example.com> 978325200 -0500
A very interesting change
We want to produce a commit object that is identical except for an
updated commit message. That sounds like a job for sed! We can strip
the existing message out like this:
git cat-file -p 519636 | sed '/^$/q'
And we can append a new commit message with the power of cat:
git cat-file -p 519636 | sed '/^$/q'; cat <<EOF
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
EOF
This will give us:
tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904
parent 4be8115640821df1565c421d8ed848bad34666e5
author Alice User <alice@example.com> 978325200 -0500
committer Alice User <alice@example.com> 978325200 -0500
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
We need to take this modified commit and store it back into the git
object database. We do that using the git hash-object command:
(git cat-file -p 519636 | sed '/^$/q'; cat <<EOF) | git hash-object -t commit --stdin -w
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
EOF
The -t commit argument instructs hash-object to create a new
commit object. The --stdin argument instructs hash-object to read
input from stdin, while the -w argument instructs hash-object to
write a new object to the object database, rather than just
calculating the hash and printing it for us.
This will print the hash of the new object on stdout. We can wrap
everything in a $(...) expression to capture the output:
newref=$(
(git cat-file -p 519636 | sed '/^$/q'; cat <<EOF) | git hash-object -t commit --stdin -w
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
EOF
)
At this point we have successfully created a new commit, but it isn’t
reachable from anywhere. If we were to run git log at this point,
everything would look the same as when we started. We need to walk
back up the tree, starting with the immediate descendant of our target
commit, replacing parent pointers as we go along.
The first thing we need is a list of revisions from our target commit
up to the current HEAD. We can get that with git rev-list:
We’ve now replaced all the descendants of the modified commit…but
git log would still show us the old history. The last thing we
need to do is update the branch point to point at the top of the
modified tree. We do that using the git update-ref command. Assuming
we’re on the master branch, the command would look like this:
git update-ref refs/heads/master $newref
And at this point, running git log show us our modified commit in
all its glory:
commit 365bc25ee1fe365d5d63d2248b77196d95d9573a
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Add detailed, high quality documentation
commit 09d6203a2b64c201dde12af7ef5a349e1ae790d7
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Fixed bug that would erroneously call rm -rf
commit fb01f35c38691eafbf44e9ee86824b594d036ba4
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
commit 4be8115640821df1565c421d8ed848bad34666e5
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
The beginning of time
Now, that was a lot of manual work. Let’s try to automate the process.
#!/bin/sh
# get the current branch name
branch=$(git rev-parse --symbolic-full-name HEAD)
# git the full commit id of our target commit (this allows us to
# specify the target as a short commit id, or as something like
# `HEAD~3` or `:/interesting`.
oldref=$(git rev-parse "$1")
# generate a replacement commit object, reading the new commit message
# from stdin.
newref=$(
(git cat-file -p $oldref | sed '/^$/q'; cat) | tee newref.txt | git hash-object -t commit --stdin -w
)
# iterate over commits between our target commit and HEAD in
# reverse order, replacing parent points with updated commit objects
for rev in $(git rev-list --reverse ${oldref}..HEAD); do
newref=$(git cat-file -p $rev |
sed "s/parent $oldref/parent $newref/" |
git hash-object -t commit --stdin -w)
oldref=$rev
done
# update the branch pointer to the head of the modified tree
git update-ref $branch $newref
If we place the above script in editmsg.sh and restore our original
revision history, we can run:
sh editmsg.sh :/interesting <<EOF
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
EOF
And end up with a new history identical to the one we created
manually:
commit 365bc25ee1fe365d5d63d2248b77196d95d9573a
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Add detailed, high quality documentation
commit 09d6203a2b64c201dde12af7ef5a349e1ae790d7
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
Fixed bug that would erroneously call rm -rf
commit fb01f35c38691eafbf44e9ee86824b594d036ba4
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
A very interesting change
Completely refactor the widget implementation to prevent
a tear in the time/space continuum when given invalid
input.
commit 4be8115640821df1565c421d8ed848bad34666e5
Author: Alice User <alice@example.com>
Date: Mon Jan 1 00:00:00 2001 -0500
The beginning of time
Caveats
The above script is intentionally simple. If you’re interesting in
doing something like this in practice, you should be aware of the
following:
The above process works great with a linear history, but will break
things if the rewriting process crosses a merge commit.
We’re assuming that the given target commit is actually reachable
from the current branch.
We’re assuming that the given target actually exists.
It’s possible to check for all of these conditions in our script, but
I’m leaving that as an exercise for the reader.
OpenShift Container Storage (OCS) from Red Hat deploys Ceph in your
OpenShift cluster (or allows you to integrate with an external Ceph
cluster). In addition to the file- and block- based volume services
provided by Ceph, OCS includes two S3-api compatible object storage
implementations.
The first option is the Ceph Object Gateway (radosgw),
Ceph’s native object storage interface. The second option called the
“Multicloud Object Gateway”, which is in fact a piece of software
named Noobaa, a storage abstraction layer that was acquired by
Red Hat in 2018. In this article I’d like to demonstrate how to
take advantage of these storage options.
What is object storage?
The storage we interact with regularly on our local computers is
block storage: data is stored as a collection of blocks on some sort
of storage device. Additional layers – such as a filesystem driver –
are responsible for assembling those blocks into something useful.
Object storage, on the other hand, manages data as objects: a single
unit of data and associated metadata (such as access policies). An
object is identified by some sort of unique id. Object storage
generally provides an API that is largely independent of the physical
storage layer; data may live on a variety of devices attached to a
variety of systems, and you don’t need to know any of those details in
order to access the data.
The most well known example of object storage service Amazon’s
S3 service (“Simple Storage Service”), first introduced in 2006.
The S3 API has become a de-facto standard for object storage
implementations. The two services we’ll be discussing in this article
provide S3-compatible APIs.
Creating buckets
The fundamental unit of object storage is called a “bucket”.
Creating a bucket with OCS works a bit like creating a persistent
volume, although instead of starting with a PersistentVolumeClaim
you instead start with an ObjectBucketClaim ("OBC"). An OBC
looks something like this when using RGW:
With OCS 4.5, your out-of-the-box choices for storageClassName will be
ocs-storagecluster-ceph-rgw, if you choose to use Ceph Radosgw, or
openshift-storage.noobaa.io, if you choose to use the Noobaa S3 endpoint.
Before we continue, I’m going to go ahead and create these resources
in my OpenShift environment. To do so, I’m going to use Kustomize
to deploy the resources described in the following kustomization.yml
file:
Running kustomize build | oc apply -f- from the directory containing
this file populates the specified namespace with the two
ObjectBucketClaims mentioned above:
$ kustomize build | oc apply -f-
objectbucketclaim.objectbucket.io/example-noobaa created
objectbucketclaim.objectbucket.io/example-rgw created
Verifying that things seem healthy:
$ oc get objectbucketclaim
NAME STORAGE-CLASS PHASE AGE
example-noobaa openshift-storage.noobaa.io Bound 2m59s
example-rgw ocs-storagecluster-ceph-rgw Bound 2m59s
Each ObjectBucketClaim will result in a OpenShift creating a new
ObjectBucket resource (which, like PersistentVolume resources, are
not namespaced). The ObjectBucket resource will be named
obc-<namespace-name>-<objectbucketclaim-name>.
$ oc get objectbucket obc-oddbit-ocs-example-example-rgw obc-oddbit-ocs-example-example-noobaa
NAME STORAGE-CLASS CLAIM-NAMESPACE CLAIM-NAME RECLAIM-POLICY PHASE AGE
obc-oddbit-ocs-example-example-rgw ocs-storagecluster-ceph-rgw oddbit-ocs-example example-rgw Delete Bound 67m
obc-oddbit-ocs-example-example-noobaa openshift-storage.noobaa.io oddbit-ocs-example example-noobaa Delete Bound 67m
Each ObjectBucket resource corresponds to a bucket in the selected
object storage backend.
Because buckets exist in a flat namespace, the OCS documentation
recommends always using generateName in the claim, rather than
explicitly setting bucketName, in order to avoid unexpected
conflicts. This means that the generated buckets will have a named
prefixed by the value in generateName, followed by a random string:
$ oc get objectbucketclaim example-rgw -o jsonpath='{.spec.bucketName}'example-rgw-425d7193-ae3a-41d9-98e3-9d07b82c9661
$ oc get objectbucketclaim example-noobaa -o jsonpath='{.spec.bucketName}'example-noobaa-2e087028-b3a4-475b-ae83-a4fa80d9e3ef
Along with the bucket itself, OpenShift will create a Secret and a
ConfigMap resource – named after your OBC – with the metadata
necessary to access the bucket.
The Secret contains AWS-style credentials for authenticating to the
S3 API:
Note that BUCKET_HOST contains the internal S3 API endpoint. You won’t be
able to reach this from outside the cluster. We’ll tackle that in just a
bit.
Accessing a bucket from a pod
The easiest way to expose the credentials in a pod is to map the keys
from both the ConfigMap and Secret as environment variables using
the envFrom directive, like this:
Note that we’re also setting AWS_CA_BUNDLE here, which you’ll need
if the internal endpoint referenced by $BUCKET_HOST is using SSL.
Inside the pod, we can run, for example, aws commands as long as we
provide an appropriate s3 endpoint. We can inspect the value of
BUCKET_PORT to determine if we need http or https:
External access to services in OpenShift is often managed via
routes. If you look at the routes available in your
openshift-storage namespace, you’ll find the following:
$ oc -n openshift-storage get route
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
noobaa-mgmt noobaa-mgmt-openshift-storage.apps.example.com noobaa-mgmt mgmt-https reencrypt None
s3 s3-openshift-storage.apps.example.com s3 s3-https reencrypt None
The s3 route provides external access to your Noobaa S3 endpoint.
You’ll note that in the list above there is no route registered for
radosgw1. There is a service registered for Radosgw named
rook-ceph-rgw-ocs-storagecluster-cephobjectstore, so we
can expose that service to create an external route by running
something like:
Once we know the Route to our S3 endpoint, we can use the
information in the Secret and ConfigMap created for us when we
provisioned the storage. We just need to replace the BUCKET_HOST
with the hostname in the route, and we need to use SSL over port 443
regardless of what BUCKET_PORT tells us.
We can extract the values into variables using something like the
following shell script, which takes care of getting the appropriate
route from the openshift-storage namespace, base64-decoding the values
in the Secret, and replacing the BUCKET_HOST value:
#!/bin/sh
bucket_host=$(oc get configmap $1 -o json | jq -r .data.BUCKET_HOST)service_name=$(cut -f1 -d. <<<$bucket_host)service_ns=$(cut -f2 -d. <<<$bucket_host)# get the externally visible hostname provided by the routepublic_bucket_host=$( oc -n $service_ns get route -o json |
jq -r '.items[]|select(.spec.to.name=="'"$service_name"'")|.spec.host')# dump configmap and secret as shell variables, replacing the# value of BUCKET_HOST in the process.( oc get configmap $1 -o json |
jq -r '.data as $data|.data|keys[]|"\(.)=\($data[.])"' oc get secret $1 -o json |
jq -r '.data as $data|.data|keys[]|"\(.)=\($data[.]|@base64d)"') | sed -e 's/^/export /' -e '/BUCKET_HOST/ s/=.*/='$public_bucket_host'/'
If we call the script getenv.sh and run it like this:
Performance of the primary PyPi service has been so bad lately that
it’s become very disruptive. Tasks that used to take a few seconds
will now churn along for 15-20 minutes or longer before completing,
which is incredibly frustrating.
I first went looking to see if there was a PyPi mirror infrastructure,
like we see with CPAN for Perl or CTAN for Tex (and similarly
for most Linux distributions). There is apparently no such beast,
I didn’t really want to set up a PyPi mirror locally, since the number
of packages I actually use is small vs. the number of packages
available. I figured there must be some sort of caching proxy
available that would act as a shim between me and PyPi, fetching
packages from PyPi and caching them if they weren’t already available
locally.
I was previously aware of Artifactory, which I suspected (and
confirmed) was capable of this, but while looking around I came across
DevPi, which unlike Artifactory is written exclusively for
managing Python packages. DevPi itself is hosted on PyPi, and the
documentation made things look easy to configure.
I started with the following Dockerfile (note I’m using
podman rather than Docker as my container runtime, but the
resulting image will work fine for either environment):
This installs both devpi-server, which provides the basic caching
for pip install, as well as devpi-web, which provides support for
pip search.
To ensure that things are initialized correctly when the container
start up, I’ve set the ENYTRYPOINT to the following script:
#!/bin/sh
if ! [ -f /root/.devpi/server ]; then
devpi-init
fi
exec "$@"
This will run devpi-init if the target directory hasn’t already been
initialized.
The repository includes a GitHub workflow that builds a new image on each commit
and pushes the result to the oddbit/devpi-server repository on
Docker Hub.
Once the image was available on Docker Hub, I created the following
systemd unit to run the service locally:
There are a couple items of note in this unitfile:
The service is exposed only on localhost using -p 127.0.0.1:3141:3141. I don’t want this service exposed on
externally visible addresses since I haven’t bothered setting up any
sort of authentication.
The service mounts a named volume for use by devpi-server via the
-v devpi:/root/.devpi command line option.
This unit file gets installed into
~/.config/systemd/user/devpi.service. Running systemctl --user enable --now devpi.service both enables the service to start at boot
and actually starts it up immediately.
With the service running, the last thing to do is configure pip to
utilize it. The following configuration, placed in
~/.config/pip/pip.conf, does the trick:
[install]
index-url = http://localhost:3141/root/pypi/+simple/
[search]
index = http://localhost:3141/root/pypi/
Now both pip install and pip search hit the local cache instead of
the upstream PyPi server, and things are generally much, much faster.
For Poetry Users
Poetry respects the pip configuration and will Just Work.
For Pipenv Users
Pipenv does not respect the pip configuration [1,
2], so you will
need to set the PIPENV_PYPI_MIRROR environment variable. E.g:
The SYM-1 is a 6502-based single-board computer produced by
Synertek Systems Corp in the mid 1970’s. I’ve had one
floating around in a box for many, many years, and after a recent
foray into the world of 6502 assembly language programming I decided
to pull it out, dust it off, and see if it still works.
The board I have has a whopping 8KB of memory, and in addition to the
standard SUPERMON monitor it has the expansion ROMs for the Synertek
BASIC interpreter (yet another Microsoft BASIC) and RAE (the “Resident
Assembler Editor”). One interacts with the board either through the
onboard hex keypad and six-digit display, or via a serial connection
at 4800bps (or lower).
[If you’re interested in Microsoft BASIC, the mist64/msbasic
repository on GitHub is a trove of information, containing the source
for multiple versions of Microsoft BASIC including the Synertek
version.]
Fiddling around with the BASIC interpreter and the onboard assembler
was fun, but I wanted to use a real editor for writing source
files, assemble them on my Linux system, and then transfer the
compiled binary to the SYM-1. The first two tasks are easy; there are
lots of editors and there are a variety of 6502 assemblers that will
run under Linux. I’m partial to ca65, part of the cc65
project (which is an incredible project that implements a C compiler
that cross-compiles C for 6502 processors). But what’s the best way to
get compiled code over to the SYM-1?
Symtool
That’s where symtool comes in. Symtool runs on your host and
talks to the SUPERMON monitor on the SYM-1 over a serial connection.
It allows you to view registers, dump and load memory, fill memory,
and execute code.
Configuration
Symtool needs to know to what serial device your SYM-1 is attached.
You can specify this using the -d <device> command line option, but
this quickly gets old. To save typing, you can instead set the
SYMTOOL_DEVICE environment variable:
The baud rate defaults to 4800bps. If for some reason you want to use
a slower speed (maybe you’d like to relive the good old days of 300bps
modems), you can use the -s command line option or the
SYMTOOL_SPEED environment variable.
Loading code into memory
After compiling your code (I’ve included the examples from the SYM-1
Technical Notes in the repository), use the load command to
load the code into the memory of the SYM-1:
$ make -C asm
[...]
$ symtool -v load 0x200 asm/countdown.bin
INFO:symtool.symtool:using port /dev/ttyUSB0, speed 4800
INFO:symtool.symtool:connecting to sym1...
INFO:symtool.symtool:connected
INFO:symtool.symtool:loading 214 bytes of data at $200
(Note the -v on the command line there; without that, symtool
won’t produce any output unless there’s an error.)
[A note on compiling code: the build logic in the asm/
directory is configured to load code at address 0x200. If you want
to load code at a different address, you will need to add the
appropriate --start-addr option to LD65FLAGS when building, or
modify the linker configuration in sym1.cfg.]
Examining memory
The above command loads the code into memory but doesn’t execute it.
We can use the dump command to examine memory. By default, dump
produces binary output. We can use that to extract code from the SYM-1
ROM or to verify that the code we just loaded was transferred
correctly:
There are two ways to run your code using symtool. If you provide
the -g option to the load command, symtool will execute your
code as soon as the load has finished:
$ symtool load -g 0x200 asm/countdown.bin
Alternatively, you can use the go command to run code that has
already been loaded onto the SYM-1:
$ symtool go 0x200
Examining registers
The registers command allows you to examine the contents of the 6502
registers:
$ symtool registers
s ff (11111111)
f b1 (10110001) +carry -zero -intr -dec -oflow +neg
a 80 (10000000)
x 00 (00000000)
y 50 (01010000)
p b0ac (1011000010101100)
Filling memory
If you want to clear a block of memory, you can use the fill
command. For example, to wipe out the code we loaded in the earlier
example:
The symtool repository includes both unit and functional tests. The
functional tests require an actual SYM-1 to be attached to your system
(with the device name in the SYMTOOL_DEVICE environment variable).
The unit tests will run anywhere.
Wrapping up
No lie, this is a pretty niche project. I’m not sure how many people
out there own a SYM-1 these days, but this has been fun to work with
and if maybe one other person finds it useful, I would consider that
a success :).
While CentOS Linux 8 (C8) is a pure rebuild of Red Hat Enterprise Linux (RHEL), CentOS Stream 8 (C8S) tracks just ahead of the current RHEL release. This means that we will have a continuous flow of new packages available before they are included in the next RHEL minor release.
What’s the current situation in RDO?
RDO has been using the latest CentOS Linux 8 to build both the OpenStack packages and the required dependencies since the Train release for both for the official CloudSIG repos and the RDO Trunk (aka DLRN) repos.
In the last few months, we have been running periodic CI jobs to validate RDO Trunk repos built on CentOS Linux 8 along with CentOS Stream 8 to find any potential issues created by OS package updates before they are shipped in CentOS Linux 8. As expected, during these tests we have not found any issue related to the buildroot environment, packages can be used for both C8 and C8S. We did find a few issues related to package updates which allowed us to propose the required fixes upstream.
What’s our plan for RDO roadmap?
RDO Wallaby (ETA is end of April 2021) will be built, tested and released only on CentOS 8 Stream.
RDO CloudSIG repos for Victoria and Ussuri will be updated and tested for both CentOS Stream and CentOS Linux 8 until end of 2021 and then continue on CentOS Stream.
We will create and test new RDO CloudSIG repos for Victoria and Ussuri on CentOS Stream 8.
The RDO Trunk repositories (aka DLRN repos) will be built and tested using CentOS 8 Stream buildroot for all releases currently using CentOS Linux 8 (since Train on)
How do we plan to implement these changes?
Some implementation details that may be of interest:
We will keep building packages just once. We will move buildroots for both DLRN and CloudSIG to use CentOS Stream 8 in the near future.
For Ussuri and Victoria CloudSIG repos,while we are supporting both C8 and C8S, we will be utilizing separated CBS Tags. This will allow us to have separated repositories, promotion jobs and package versions for each OS.
In order to reduce the impact of potential issues and discover issues related to C8S as soon as possible, we will put more focus on periodic jobs on C8S.
At a later stage, we will move the CI jobs used to gate changes in distgits to use C8S instead of C8 for all RDO releases where we use CentOS 8.
The CentOS/RHEL team has made public their interest in applying Continuous Delivery approach to CentOS Stream to provide a stable CentOS Stream using gating integration jobs. Our intent is to collaborate with the CentOS team on any initiatives that will help to validate RDO as early in the delivery pipeline as possible and reduce the impact on potential issues.
What’s next?
We plan to start the activities needed to carry out this plan in the next weeks.
We will continue discussing and sharing the progress during the RDO weekly meetings, feel free to join us if you are interested.
Also, If you have any question or suggestion related to these changes, don’t hesitate to contact us in the #rdo freenode channel or using the RDO mailing lists.
Recently, I bought a couple of Raspberry Pi 4, one with 4 GB and 2
equipped with 8 GB of RAM. When I bought the first one, there was no
option to get bigger memory. However, I saw this as a game and thought
to give this a try. I also bought SSDs for these and USB3 to SATA
adapters. Before purchasing anything, you may want to take a look at
James Archers page.
Unfortunately, there are a couple on adapters on the marked, which
don't work that well.
Deploying Fedora 33 Server
Initially, I followed the description
to deploy Fedora 32; it works the same way for Fedora 33 Server (in my case here).
Because ceph requires a partition (or better: a whole disk), I used the
traditional setup using partitions and no LVM.
Deploying Kubernetes
git clone https://github.com/kubernetes-sigs/kubespray
cd kubespray
I followed the documentation and created an inventory. For the container
runtime, I picked crio, and as calico as network plugin.
Because of an issue,
I had to patch roles/download/defaults/main.yml:
Let’s say you have a couple of sensors attached to an ESP8266 running
MicroPython. You’d like to sample them at different frequencies
(say, one every 60 seconds and one every five minutes), and you’d like
to do it as efficiently as possible in terms of power consumption.
What are your options?
If we don’t care about power efficiency, the simplest solution is
probably a loop like this:
import machine
lastrun_1 = 0
lastrun_2 = 0
while True:
now = time.time()
if (lastrun_1 == 0) or (now - lastrun_1 >= 60):
read_sensor_1()
lastrun_1 = now
if (lastrun_2 == 0) or (now - lastrun_2 >= 300):
read_sensor_2()
lastrun_2 = now
machine.idle()
If we were only reading a single sensor (or multiple sensors at the
same interval), we could drop the loop and juse use the ESP8266’s deep
sleep mode (assuming we have wired things properly):
This will wake up, read the sensor, then sleep for 60 seconds, at
which point the device will reboot and repeat the process.
If we want both use deep sleep and run tasks at different intervals,
we can effectively combine the above two methods. This requires a
little help from the RTC, which in addition to keeping time also
provides us with a small amount of memory (492 bytes when using
MicroPython) that will persist across a deepsleep/reset cycle.
The machine.RTC class includes a memory method that provides
access to the RTC memory. We can read the memory like this:
Note that rtc.memory() will always return a byte string.
We write to it like this:
rtc.memory('somevalue')
Lastly, note that the time maintained by the RTC also persists across
a deepsleep/reset cycle, so that if we call time.time() and then
deepsleep for 10 seconds, when the module boots back up time.time()
will show that 10 seconds have elapsed.
We’re going to implement a solution similar to the loop presented at
the beginning of this article in that we will store the time at which
at task was last run. Because we need to maintain two different
values, and because the RTC memory operates on bytes, we need a way to
serialize and deserialize a pair of integers. We could use functions
like this:
import json
def store_time(t1, t2):
rtc.memory(json.dumps([t1, t2]))
def load_time():
data = rtc.memory()
if not data:
return [0, 0]
try:
return json.loads(data)
except ValueError:
return [0, 0]
The load_time method returns [0, 0] if either (a) the RTC memory
was unset or (b) we were unable to decode the value stored in memory
(which might happen if you had previously stored something else
there).
You don’t have to use json for serializing the data we’re storing in
the RTC; you could just as easily use the struct module:
import struct
def store_time(t1, t2):
rtc.memory(struct.pack('ll', t1, t2))
def load_time():
data = rtc.memory()
if not data:
return [0, 0]
try:
return struct.unpack('ll', data)
except ValueError:
return [0, 0]
Once we’re able to store and retrieve data from the RTC, the main part
of our code ends up looking something like this:
lastrun_1, lastrun_2 = load_time()
now = time.time()
something_happened = False
if lastrun_1 == 0 or (now - lastrun_1 > 60):
read_sensor_1()
lastrun_1 = now
something_happened = True
if lastrun_2 == 0 or (now - lastrun_2 > 300):
read_sensor_2()
lastrun_2 = now
something_happened = True
if something_happened:
store_time(lastrun_1, lastrun_2)
deepsleep(60000)
This code will wake up every 60 seconds. That means it will always run
the read_sensor_1 task, and it will run the read_sensor_2 task
every five minutes. In between, the ESP8266 will be in deep sleep
mode, consuming around 20µA. In order to avoid too many unnecessary
writes to RTC memory, we only store values when lastrun_1 or
lastrun_2 has changed.
While developing your code, it can be inconvenient to have the device
enter deep sleep mode (because you can’t just ^C to return to the
REPL). You can make the deep sleep behavior optional by wrapping
everything in a loop, and optionally calling deepsleep at the end of
the loop, like this:
lastrun_1, lastrun_2 = load_time()
while True:
now = time.time()
something_happened = False
if lastrun_1 == 0 or (now - lastrun_1 > 60):
read_sensor_1()
lastrun_1 = now
something_happened = True
if lastrun_2 == 0 or (now - lastrun_2 > 300):
read_sensor_2()
lastrun_2 = now
something_happened = True
if something_happened:
store_time(lastrun_1, lastrun_2)
if use_deep_sleep:
deepsleep(60000)
else:
machine.idle()
If the variable use_deepsleep is True, this code will perform as
described in the previous section, waking once every 60 seconds. If
use_deepsleep is False, this will use a busy loop.
While reviewing the comments on the Ironic spec, for Secure RBAC. I had to ask myself if the “project” construct makes sense for Ironic. I still think it does, but I’ll write this down to see if I can clarify it for me, and maybe for you, too.
Baremetal servers change. The whole point of Ironic is to control
the change of Baremetal servers from inanimate pieces of metal to
“really useful engines.” This needs to happen in a controlled and
unsurprising way.
Ironic the server does what it is told. If a new piece of metal
starts sending out DHCP requests, Ironic is going to PXE boot it. This
is the start of this new piece of metals journey of self discovery. At
least as far as Ironic is concerned.
But really, someone had to rack and wire said piece of metal. Likely the person that did this is not the person that is going to run workloads on it in the end. They might not even work for the same company; they might be a delivery person from Dell or Supermicro. So, once they are done with it, they don’t own it any more.
Who does? Who owns a piece of metal before it is enrolled in the OpenStack baremetal service?
No one. It does not exist.
Ok, so lets go back to someone pushing the button, booting our server for the first time, and it doing its PXE boot thing.
Or, we get the MAC address and enter that into the ironic database, so that when it does boot, we know about it.
Either way, Ironic is really the playground monitor, just making sure it plays nice.
What if Ironic is a multi-tenant system? Someone needs to be able to transfer the baremetal server from where ever it lands up front to the people that need to use it.
I suspect that ransferring metal from project to project is going to be one of the main use cases after the sun has set on day one.
So, who should be allowed to say what project a piece of baremetal can go to?
Well, in Keystone, we have the idea of hierarchy. A Project is owned
by a domain, and a project can be nested inside another project.
But this information is not passed down to Ironic. There is no way to get a token for a project that shows its parent information. But a remote service could query the project hierarchy from Keystone.
Say I want to transfer a piece of metal from one project to another.
Should I have a token for the source project or the remote project.
Ok, dump question, I should definitely have a token for the source
project. The smart question is whether I should also have a token for
the destination project.
Sure, why not. Two tokens. One has the “delete” role and one that has the “create” role.
The only problem is that nothing like this exists in Open Stack. But it should.
We could fake it with hierarchy; I can pass things up and down the
project tree. But that really does not one bit of good. People don’t
really use the tree like that. They should. We built a perfectly nice
tree and they ignore it. Poor, ignored, sad, lonely tree.
Actually, it has no feelings. Please stop anthropomorphising the tree.
What you could do is create the destination object, kind of a potential piece-of-metal or metal-receiver. This receiver object gets a UUID. You pass this UUID to the “move” API. But you call the MOVE api with a token for the source project. The move is done atomically. Lets call this thing identified by a UUID a move-request.
The order of operations could be done in reverse. The operator could create the move request on the source, and then pass that to the receiver. This might actually make mores sense, as you need to know about the object before you can even think to move it.
Both workflows seem to have merit.
And…this concept seems to be something that OpenStack needs in general.
Infact, why should the API not be a generic API. I mean, it would have to be per service, but the same API could be used to transfer VMs between projects in Nova nad between Volumes in Cinder. The API would have two verbs one for creating a new move request, and one for accepting it.
POST /thingy/v3.14/resource?resource_id=abcd&destination=project_id
If this is called with a token, it needs to be scoped. If it is scoped to the project_id in the API, it creates a receiving type request. If it is scoped to the project_id that owns the resource, it is a sending type request. Either way, it returns an URL. Call GET on that URL and you get information about the transfer. Call PATCH on it with the appropriately scoped token, and the resource is transferred. And maybe enough information to prove that you know what you are doing: maybe you have to specify the source and target projects in that patch request.
A foolish consistency is the hobgoblin of little minds.
Edit: OK, this is not a new idea. Cinder went through the same thought process according to Duncan Thomas. The result is this API: https://docs.openstack.org/api-ref/block-storage/v3/index.html#volume-transfer
Some tests in CI are configured to use `--skip-tags`. You can do this for your local tests too by setting the appropriate environment variables. For example:
<p>I recently put together a short animation showing the spread of Covid
throughout the Northeast United States:</p>
<div style="position: relative; padding-bottom: 56.25%; height: 0; overflow: hidden;">
<iframe allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen="allowfullscreen" loading="eager" referrerpolicy="strict-origin-when-cross-origin" src="https://www.youtube.com/embed/zGN_zEzd_TE?autoplay=0&controls=1&end=0&loop=0&mute=0&start=0" style="position: absolute; top: 0; left: 0; width: 100%; height: 100%; border:0;" title="YouTube video"
></iframe>
</div>
<p>I thought it might be interesting to walk through the process I used to
create the video. The steps described in this article aren’t exactly
what I used (I was dealing with data in a <a href="https://postgis.net/">PostGIS</a> database, and in
the interests of simplicity I wanted instructions that can be
accomplished with just QGIS), but they end up in the same place.</p>
<h2 id="data-sources">Data sources</h2>
<p>Before creating the map, I had to find appropriate sources of data. I
needed three key pieces of information:</p>
<ol>
<li>State and county outlines</li>
<li>Information about population by county</li>
<li>Information about Covid cases over time by county</li>
</ol>
<h3 id="us-census-data">US Census Data</h3>
<p>I was able to obtain much of the data from the US Census website,
<a href="https://data.census.gov">https://data.census.gov</a>. Here I was able to find both tabular
demographic data (population information) and geographic data (state
and county cartographic borders):</p>
<ul>
<li>
<p><a href="https://www2.census.gov/programs-surveys/popest/datasets/2010-2019/counties/totals/co-est2019-alldata.csv">Population estimates</a></p>
<p>This dataset contains population estimates by county from 2010
through 2019. This comes from the US Census “<a href="https://www.census.gov/programs-surveys/popest.html">Population Estimates
Program</a>” (PEP).</p>
</li>
<li>
<p><a href="https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_county_5m.zip">County outlines</a></p>
<p>This dataset contains US county outlines provided by the US Census.</p>
</li>
<li>
<p><a href="https://www2.census.gov/geo/tiger/GENZ2018/shp/cb_2018_us_state_5m.zip">State outlines</a></p>
<p>This dataset contains US state outlines provided by the US Census.</p>
</li>
</ul>
<p>The tabular data is provided in <a href="https://en.wikipedia.org/wiki/Comma-separated_values">CSV</a> (comma-separated value)
format, which is a simple text-only format that can be read by a
variety of software (including spreadsheet software such as Excel or
Google Sheets).</p>
<p>The geographic data is available as both a <a href="https://en.wikipedia.org/wiki/Shapefile">shapefile</a> and as a
<a href="https://en.wikipedia.org/wiki/Keyhole_Markup_Language">KML</a> file. A <em>shapefile</em> is a relatively standard format for
exchanging geographic data. You generally need some sort of <a href="https://en.wikipedia.org/wiki/Geographic_information_system">GIS
software</a> in order to open and manipulate a shapefile (a topic that
I will cover later on in this article). KML is another format for
sharing geographic data that was developed by Google as part of Google
Earth.</p>
<h3 id="new-york-times-covid-data">New York Times Covid Data</h3>
<p>The New York Times maintains a <a href="https://github.com/nytimes/covid-19-data">Covid dataset</a> (because our
government is both unable and unwilling to perform this basic public
service) in CSV format that tracks Covid cases and deaths in the
United States, broken down both by state and by county.</p>
<h2 id="software">Software</h2>
<p>In order to build something like this map you need a Geographic
Information System (GIS) software package. The 800 pound gorilla of
GIS software is <a href="https://www.esri.com/en-us/arcgis/about-arcgis/overview">ArcGIS</a>, a capable but pricey commercial package
that may cost more than the casual GIS user is willing to pay.
Fortunately, there are some free alternatives available.</p>
<p>Google’s <a href="https://www.google.com/earth/versions/#earth-pro">Google Earth Pro</a> has a different focus from most other
GIS software (it is designed more for exploration/educational use than
actual GIS work), but it is able to open and display a variety of GIS
data formats, including the shapefiles used in this project.</p>
<p><a href="https://qgis.org/en/site/">QGIS</a> is a highly capable <a href="https://www.redhat.com/en/topics/open-source/what-is-open-source">open source</a> GIS package, available
for free for a variety of platforms including MacOS, Windows, and
Linux. This is the software that I used to create the animated map,
and the software we’ll be working with in the rest of this article.</p>
<h2 id="preparing-the-data">Preparing the data</h2>
<h3 id="geographic-filtering">Geographic filtering</h3>
<p>I was initially planning on creating a map for the entire United
States, but I immediately ran into a problem: with over 3,200 counties
in the US and upwards of 320 data points per county in the Covid
dataset, that was going to result in over 1,000,000 geographic
features. On my computer, QGIS wasn’t able to handle a dataset of
that size. So the first step is limiting the data we’re manipulating
to something smaller; I chose New York and New England.</p>
<p>We start by adding the <code>cb_2018_us_state_5m</code> map to QGIS. This gives
us all 50 states (and a few territories):</p>
<figure class="left" >
<img src="states-unfiltered.png" />
</figure>
<p>To limit this to our target geography, we can select “Filter…” from
the layer context menu and apply the following filter:</p>
<pre tabindex="0"><code>"NAME" in (
'New York',
'Massachusetts',
'Rhode Island',
'Connecticut',
'New Hampshire',
'Vermont',
'Maine'
)
</code></pre><p>This gives us:</p>
<figure class="left" >
<img src="states-filtered.png" />
</figure>
<p>Next, we need to load in the county outlines that cover the same
geographic area. We start by adding the <code>cb_2018_us_county_5m</code>
dataset to QGIS, which gets us:</p>
<figure class="left" >
<img src="counties-unfiltered.png" />
</figure>
<p>There are several ways we could limit the counties to just those in
our target geography. One method is to use the “Clip…” feature in
the “Vector->Geoprocessing Tools” menu. This allows to “clip” one
vector layer (such as our county outlines) using another layer (our
filtered state layer).</p>
<p>We select “Vector->Geoprocessing Tools->Clip…”, and then fill
in in the resulting dialog as follows:</p>
<ul>
<li>For “Input layer”, select <code>cb_2018_us_county_5m</code>.</li>
<li>For “Overlay layer”, select <code>cb_2018_us_state_5m</code>.</li>
</ul>
<p>Now select the “Run” button. You should end up with a new layer named
<code>Clipped</code>. Hide the original <code>cb_2018_us_county_5m</code> layer, and rename
<code>Clipped</code> to <code>cb_2018_us_county_5m_clipped</code>. This gives us:</p>
<figure class="left" >
<img src="counties-clipped.png" />
</figure>
<p>Instead of using the “Clip…” algorithm, we could have created a
<a href="https://docs.qgis.org/3.16/en/docs/user_manual/managing_data_source/create_layers.html#creating-virtual-layers">virtual layer</a> and performed a <a href="http://wiki.gis.com/wiki/index.php/Spatial_Join#:~:text=A%20Spatial%20join%20is%20a,spatially%20to%20other%20feature%20layers.">spatial join</a> between the state
and county layers; unfortunately, due to issue <a href="https://github.com/qgis/QGIS/issues/40503">#40503</a>, it’s not
possible to use virtual layers with this dataset (or really any
dataset, if you have numeric data you care about).</p>
<h3 id="merging-population-data-with-our-geographic-data">Merging population data with our geographic data</h3>
<p>Add the population estimates to our project. Select “Layer->Add
Layer->Add Delimited Text Layer…”, find the
<code>co-est2019-alldata.csv</code> dataset and add it to the project. This layer
doesn’t have any geographic data of its own; we need to associate it
with one of our other layers in order to make use of it. We can this
by using a <a href="https://www.qgistutorials.com/en/docs/3/performing_table_joins.html">table join</a>.</p>
<p>In order to perform a table join, we need a single field in each layer
that corresponds to a field value in the other layer. The counties
dataset has a <code>GEOID</code> field that combines the state and county <a href="https://transition.fcc.gov/oet/info/maps/census/fips/fips.txt">FIPS
codes</a>, but the population dataset has only individual state and
county codes. We can create a new <a href="https://docs.qgis.org/3.16/en/docs/user_manual/working_with_vector/attribute_table.html#creating-a-virtual-field">virtual field</a> in the population
layer that combines these two values in order to provide an
appropriate target field for the table join.</p>
<p>Open the attribute table for population layer, and click on the “Open
field calculator” button (it looks like an abacus). Enter <code>geoid</code> for
the field name, select the “Create virtual field” checkbox, and select
“Text (string)” for the field type. In the “Expression” field, enter:</p>
<pre tabindex="0"><code>lpad(to_string("STATE"), 2, '0') || lpad(to_string("COUNTY"), 3, '0')
</code></pre>
<figure class="left" >
<img src="create-virtual-field.png" />
</figure>
<p>When you return the to attribute table, you will see a new <code>geoid</code>
field that contains our desired value. We can now perform the table
join.</p>
<p>Open the properties for the <code>cb_2018_us_county_5m_clipped</code> layer we
created earlier, and select the “Joins” tab. Click on the “+” button.
For “Join layer”, select <code>co-est2019-alldata</code>. Select <code>geoid</code> for
“Join field” and <code>GEOID</code> for target field. Lastly, select the “Custom
field name prefix” checkbox and enter <code>pop_</code> in the field, then click
“OK”.</p>
<figure class="left" >
<img src="county-join-population.png" />
</figure>
<p>If you examine the attribute table for the layer, you will see the
each county feature is now linked to the appropriate population
data for that county.</p>
<h3 id="merging-covid-data-with-our-geographic-data">Merging Covid data with our geographic data</h3>
<p>This is another table join operation, but the process is going to be a
little different. The previous process assumes a 1-1 mapping between
features in the layers being joined, but the Covid dataset has many
data points for each county. We need a solution that will produce the
desired 1-many mapping.</p>
<p>We can achieve this using the “Join attributes by field value”
action in the “Processing” toolbox.</p>
<p>Start by adding the <code>us-counties.csv</code> file from the NYT covid dataset
to the project.</p>
<p>Select “Toolbox->Processing” to show the Processing toolbox, if
it’s not already visible. In the “Search” field, enter “join”, and
then look for “Join attributes by field value” in the “Vector general”
section.</p>
<p>Double click on this to open the input dialog. For “Input layer”,
select <code>cb_2018_us_county_5m_clipped</code>, and “Table field” select
<code>GEOID</code>. For “Input layer 2”, select <code>us-counties</code>, and for “Table
field 2” select <code>fips</code>. In the “Join type” menu, select “Create
separate feature for each matching feature (one-to-many)”. Ensure the
“Discard records which could not be joined” is checked. Enter <code>covid_</code>
in the “Joined field prefix [optional]” field (this will cause the
fields in the resulting layer to have names like <code>covid_date</code>,
<code>covid_cases</code>, etc). Click the “Run” button to create the new layer.</p>
<figure class="left" >
<img src="county-join-covid.png" />
</figure>
<p>You will end up with a new layer named “Joined layer”. I suggest
renaming this to <code>cb_2018_us_county_5m_covid</code>. If you enable the “show
feature count” checkbox for your layers, you will see that while the
<code>cb_2018_us_county_5m_clipped</code> has 129 features, the new
<code>cb_2018_us_county_5m_covid</code> layer has over 32,000 features. That’s because
for each county, there are around 320 data points tracking Covid cases
(etc) over time.</p>
<figure class="left" >
<img src="layers-feature-count.png" />
</figure>
<h2 id="styling">Styling</h2>
<h3 id="creating-outlines">Creating outlines</h3>
<p>The only layer on our map that should have filled features will be the
covid data layer. We want to configure our other layers to only
display outlines.</p>
<p>First, arrange the layers in the following order (from top to bottom):</p>
<ol>
<li>cb_2018_us_state_5m</li>
<li>cb_2018_us_county_5m_clipped</li>
<li>cb_2018_us_county_5m_covid</li>
</ol>
<p>The order of the csv layers doesn’t matter, and if you still have the
original <code>cb_2018_us_county_5m</code> layer in your project it should be
hidden.</p>
<p>Configure the state layer to display outlines. Right click on the
layer and select “Properties”, then select the “Symbology” tab. Click
on the “Simple Fill” item at the top, then in the “Symbol layer type”
menu select “Simple Line”. Set the stroke width to 0.66mm.</p>
<p>As long as we’re here, let’s also enable labels for the state layer.
Select the “Labels” tab, then set the menu at the top to “Single
Labels”. Set the “Value” field to “Name”. Click the “Apply” button to
show the labels on the map without closing the window; now adjust the
font size (and click “Apply” again) until things look the way you
want. To make the labels a bit easier to read, select the “Buffer”
panel, and check the “Draw text buffer” checkbox.</p>
<p>Now do the same thing (except don’t enable labels) with the
<code>cb_2018_us_county_5m_clipped</code> layer, but set the stroke width to
0.46mm.</p>
<p>If you hide the the Covid layer, your map should look like this (don’t
forget to unhide the Covid layer for the next step):</p>
<figure class="left" >
<img src="map-outlines.png" />
</figure>
<h3 id="creating-graduated-colors">Creating graduated colors</h3>
<p>Open the properties for the <code>cb_2018_us_county_5m_covid</code> layer, and
select the “Symbology” tab. At the top of the symbology panel is a
menu currently set to “Single Symbol”. Set this to “Graduated”.</p>
<p>Open the expression editor for the “Value” field, and set it to:</p>
<pre tabindex="0"><code>(to_int("cases") / "pop_POPESTIMATE2019") * 1000000
</code></pre><p>Set the “Color ramp” to “Spectral”, and then select “Invert color
ramp”.</p>
<p>Ensure the “Mode” menu is set to “Equal count (Quantile)”, and then
set “Classes” to 15. This will give a set of graduated categories that
looks like this:</p>
<figure class="left" >
<img src="graduated-categories.png" />
</figure>
<p>Close the properties window. Your map should look something like this:</p>
<figure class="left" >
<img src="map-graduated-1.png" />
</figure>
<p>That’s not very exciting yet, is it? Let’s move on to the final
section of this article.</p>
<h2 id="animating-the-data">Animating the data</h2>
<p>For this final step, we need to enable the QGIS <a href="https://plugins.qgis.org/plugins/timemanager/">TimeManager</a>
plugin. Install the TimeManager plugin if it’s not already installed:
open the plugin manager (“Plugins->Manage and Install Plugins…”),
and ensure both that TimeManager is installed and that it is enabled
(the checkbox to the left of the plugin name is checked).</p>
<p>Return to the project and open the TimeManger panel: select
“Plugins->TimeManager->Toggle visbility”. This will display the
following panel below the map:</p>
<figure class="left" >
<img src="timemanager-panel-initial.png" />
</figure>
<p>Make sure that the “Time frame size” is set to “1 days”.</p>
<p>Click the “Settings” button to open the TimeManager settings window,
then select the “Add layer” button. In the resulting window, select
the <code>cb_2018_us_county_5m_covid</code> layer in the “Layer” menu, the select
the <code>covid_date</code> column in the “Start time” menu. Leave all other
values at their defaults and click “OK” to return to the TimeManager
settings.</p>
<figure class="left" >
<img src="timemanager-add-layer.png" />
</figure>
<p>You will see the layer we just added listed in the “Layers” list. Look
for the “Time Format” column in this list, which will say “TO BE
INFERRED”. Click in this column and change the value to <code>%Y-%m-%d</code> to
match the format of the dates in the <code>covid_date</code> field.</p>
<figure class="left" >
<img src="timemanager-settings-final.png" />
</figure>
<p>You may want to change “Show frame for” setting from the default to
something like 50 milliseconds. Leave everything else at the defaults
and click the “OK” button.</p>
<p>Ensure that the TimeManager is enabled by clicking on the “power
button” in the TimeManager panel. TimeManager is enabled when the
power button is green.</p>
<p>Disabled:</p>
<figure class="left" >
<img src="timemanager-disabled.png" />
</figure>
<p>Enabled:</p>
<figure class="left" >
<img src="timemanager-enabled.png" />
</figure>
<p>Once TimeManager is enabled, you should be able to use the slider to
view the map at different times. For example, here’s the map in early
May:</p>
<figure class="left" >
<img src="timemanager-early-may.png" />
</figure>
<p>And here it is in early November:</p>
<figure class="left" >
<img src="timemanager-early-november.png" />
</figure>
<p>To animate the map, click the play button in the bottom left of the
TimeManager panel.</p>
<p>You can export the animation to a video using the “Export Video”
button. Assuming that you have <a href="https://ffmpeg.org/">ffmpeg</a> installed, you can select an
output directory, select the “Video (required ffmpeg …)” button,
then click “OK”. You’ll end up with (a) a PNG format image file for
each frame and (b) a file named <code>out.mp4</code> containing the exported
video.</p>
<h2 id="datasets">Datasets</h2>
<p>I have made all the data referenced in this post available at
<a href="https://github.com/larsks/ne-covid-map">https://github.com/larsks/ne-covid-map</a>.</p>
Folks running the official postgres image in OpenShift will often encounter a problem when first trying to boot a Postgres container in OpenShift. Given a pod description something like this:
apiVersion: v1 kind: Pod metadata: name: postgres spec: containers: - name: postgres image: postgres:13 ports: - containerPort: 5432 volumeMounts: - mountPath: /var/lib/postgresql/data name: postgres-data envFrom: - secretRef: name: postgres-secret volumes: - name: postgres-data persistentVolumeClaim: claimName: postgres-data-pvc The container will fail to start and the logs will show the following error:
Look back at our Pushing Keystone over the Edge presentation from the OpenStack Summit. Many of the points we make are problems faced by any application trying to scale across multiple datacenters. Cassandra is a database designed to deal with this level of scale. So Cassandra may well be a better choice than MySQL or other RDBMS as a datastore to Keystone. What would it take to enable Cassandra support for Keystone?
Lets start with the easy part: defining the tables. Lets look at how we define the Federation back end for SQL. We use SQL Alchemy to handle the migrations: we will need something comparable for Cassandra Query Language (CQL) but we also need to translate the table definitions themselves.
Before we create the tables, we need to create keyspace. I am going to make separate keyspaces for each of the subsystems in Keystone: Identity, Assignment, Federation, and so on. Here’s the Federated one:
CREATE KEYSPACE keystone_federation WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1': '3'} AND durable_writes = true;
The comparable CQL to create a table would look like this:
CREATE TABLE identity_provider (id text PRIMARY KEY , enables boolean , description text);
However, when I describe the schema to view the table defintion, we see that there are many tuning and configuration parameters that are defaulted:
CREATE TABLE federation.identity_provider (
id text PRIMARY KEY,
description text,
enables boolean
) WITH additional_write_policy = '99p'
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND cdc = false
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '16', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND default_time_to_live = 0
AND extensions = {}
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair = 'BLOCKING'
AND speculative_retry = '99p';
I don’t know Cassandra well enough to say if these are sane defaults to have in production. I do know that someone, somewhere, is going to want to tweak them, and we are going to have to provide a means to do so without battling the upgrade scripts. I suspect we are going to want to only use the short form (what I typed into the CQL prompt) in the migrations, not the form with all of the options. In addition, we might want an if not exists clause on the table creation to allow people to make these changes themselves. Then again, that might make things get out of sync. Hmmm.
There are three more entities in this back end:
CREATE TABLE federation_protocol (id text, idp_id text, mapping_id text, PRIMARY KEY(id, idp_id) );
cqlsh:federation> CREATE TABLE mapping (id text primary key, rules text, );
CREATE TABLE service_provider ( auth_url text, id text primary key, enabled boolean, description text, sp_url text, RELAY_STATE_PREFIX text);
One thing that is interesting is that we will not be limiting the ID fields to 32, 64, or 128 characters. There is no performance benefit to doing so in Cassandra, nor is there any way to enforce the length limits. From a Keystone perspective, there is not much value either; we still need to validate the UUIDs in Python code. We could autogenerate the UUIDs in Cassandra, and there might be some benefit to that, but it would diverge from the logic in the Keystone code, and explode the test matrix.
There is only one foreign key in the SQL section; the federation protocol has an idp_id that points to the identity provider table. We’ll have to accept this limitation and ensure the integrity is maintained in code. We can do this by looking up the Identity provider before inserting the protocol entry. Since creating a Federated entity is a rare and administrative task, the risk here is vanishingly small. It will be more significant elsewhere.
For access to the database, we should probably use Flask-CQLAlchemy. Fortunately, Keystone is already a Flask based project, so this makes the two projects align.
For migration support, It looks like the best option out there is cassandra-migrate.
An effort like this would best be started out of tree, with an expectation that it would be merged in once it had shown a degree of maturity. Thus, I would put it into a namespace that would not conflict with the existing keystone project. The python imports would look like:
from keystone.cassandra import migrations
from keystone.cassandra import identity
from keystone.cassandra import federation
This could go in its own git repo and be separately pip installed for development. The entrypoints would be registered such that the configuration file would have entries like:
[application_credential]
driver = cassandra
Any tuning of the database could be put under a [cassandra] section of the conf file, or tuning for individual sections could be in keys prefixed with cassanda_ in the appropriate sections, such as application_credentials as shown above.
It might be interesting to implement a Cassandra token backend and use the default_time_to_live value on the table to control the lifespan and automate the cleanup of the tables. This might provide some performance benefit over the fernet approach, as the token data would be cached. However, the drawbacks due to token invalidation upon change of data would far outweigh the benefits unless the TTL was very short, perhaps 5 minutes.
Just making it work is one thing. In a follow on article, I’d like to go through what it would take to stretch a cluster from one datacenter to another, and to make sure that the other considerations that we discussed in that presentation are covered.
The RDO community is pleased to announce the general availability of the RDO build for OpenStack Victoria for RPM-based distributions, CentOS Linux and Red Hat Enterprise Linux. RDO is suitable for building private, public, and hybrid clouds. Victoria is the 22nd release from the OpenStack project, which is the work of more than 1,000 contributors from around the world.
The release is already available on the CentOS mirror network at http://mirror.centos.org/centos/8/cloud/x86_64/openstack-victoria/.
The RDO community project curates, packages, builds, tests and maintains a complete OpenStack component set for RHEL and CentOS Linux and is a member of the CentOS Cloud Infrastructure SIG. The Cloud Infrastructure SIG focuses on delivering a great user experience for CentOS Linux users looking to build and maintain their own on-premise, public or hybrid clouds.
All work on RDO and on the downstream release, Red Hat OpenStack Platform, is 100% open source, with all code changes going upstream first.
PLEASE NOTE: RDO Victoria provides packages for CentOS8 and python 3 only. Please use the Train release, for CentOS7 and python 2.7.
Interesting things in the Victoria release include:
With the Victoria release, source tarballs are validated using the upstream GPG signature. This certifies that the source is identical to what is released upstream and ensures the integrity of the packaged source code.
With the Victoria release, openvswitch/ovn are not shipped as part of RDO. Instead RDO relies on builds from the CentOS NFV SIG.
Some new packages have been added to RDO during the Victoria release:
ansible-collections-openstack: This package includes OpenStack modules and plugins which are supported by the OpenStack community to help with the management of OpenStack infrastructure.
ansible-tripleo-ipa-server: This package contains Ansible for configuring the FreeIPA server for TripleO.
python-ibmcclient: This package contains the python library to communicate with HUAWEI iBMC based systems.
puppet-powerflex: This package contains the puppet module needed to deploy PowerFlex with TripleO.
The following packages have been retired from the RDO OpenStack distribution in the Victoria release:
The Congress project, an open policy framework for the cloud, has been retired upstream and from the RDO project in the Victoria release.
neutron-fwaas, the Firewall as a Service driver for neutron, is no longer maintained and has been removed from RDO.
Other highlights of the broader upstream OpenStack project may be read via https://releases.openstack.org/victoria/highlights.
Contributors During the Victoria cycle, we saw the following new RDO contributors:
Amy Marrich (spotz) Daniel Pawlik Douglas Mendizábal Lance Bragstad Martin Chacon Piza Paul Leimer Pooja Jadhav Qianbiao NG Rajini Karthik Sandeep Yadav Sergii Golovatiuk Steve Baker
Welcome to all of you and Thank You So Much for participating!
But we wouldn’t want to overlook anyone. A super massive Thank You to all 58 contributors who participated in producing this release. This list includes commits to rdo-packages, rdo-infra, and redhat-website repositories:
Adam Kimball Ade Lee Alan Pevec Alex Schultz Alfredo Moralejo Amol Kahat Amy Marrich (spotz) Arx Cruz Bhagyashri Shewale Bogdan Dobrelya Cédric Jeanneret Chandan Kumar Damien Ciabrini Daniel Pawlik Dmitry Tantsur Douglas Mendizábal Emilien Macchi Eric Harney Francesco Pantano Gabriele Cerami Gael Chamoulaud Gorka Eguileor Grzegorz Grasza Harald Jensås Iury Gregory Melo Ferreira Jakub Libosvar Javier Pena Joel Capitao Jon Schlueter Lance Bragstad Lon Hohberger Luigi Toscano Marios Andreou Martin Chacon Piza Mathieu Bultel Matthias Runge Michele Baldessari Mike Turek Nicolas Hicher Paul Leimer Pooja Jadhav Qianbiao.NG Rabi Mishra Rafael Folco Rain Leander Rajini Karthik Riccardo Pittau Ronelle Landy Sagi Shnaidman Sandeep Yadav Sergii Golovatiuk Slawek Kaplonski Soniya Vyas Sorin Sbarnea Steve Baker Tobias Urdin Wes Hayutin Yatin Karel
The Next Release Cycle At the end of one release, focus shifts immediately to the next release i.e Wallaby.
Get Started There are three ways to get started with RDO.
To spin up a proof of concept cloud, quickly, and on limited hardware, try an All-In-One Packstack installation. You can run RDO on a single node to get a feel for how it works.
For a production deployment of RDO, use TripleO and you’ll be running a production cloud in short order.
Finally, for those that don’t have any hardware or physical resources, there’s the OpenStack Global Passport Program. This is a collaborative effort between OpenStack public cloud providers to let you experience the freedom, performance and interoperability of open source infrastructure. You can quickly and easily gain access to OpenStack infrastructure via trial programs from participating OpenStack public cloud providers around the world.
Get Help The RDO Project has our users@lists.rdoproject.org for RDO-specific users and operators. For more developer-oriented content we recommend joining the dev@lists.rdoproject.org mailing list. Remember to post a brief introduction about yourself and your RDO story. The mailing lists archives are all available at https://mail.rdoproject.org. You can also find extensive documentation on RDOproject.org.
The #rdo channel on Freenode IRC is also an excellent place to find and give help.
We also welcome comments and requests on the CentOS devel mailing list and the CentOS and TripleO IRC channels (#centos, #centos-devel, and #tripleo on irc.freenode.net), however we have a more focused audience within the RDO venues.
Get Involved To get involved in the OpenStack RPM packaging effort, check out the RDO contribute pages, peruse the CentOS Cloud SIG page, and inhale the RDO packaging documentation.
Join us in #rdo and #tripleo on the Freenode IRC network and follow us on Twitter @RDOCommunity. You can also find us on Facebook and YouTube.
The sheer number of projects and problem domains covered by OpenStack was overwhelming. I never learned several of the other projects under the big tent. One project that is getting relevant to my day job is Ironic, the bare metal provisioning service. Here are my notes from spelunking the code.
I want just Ironic. I don’t want Keystone (personal grudge) or Glance or Neutron or Nova.
Ironic will write files to e.g. /var/lib/tftp and /var/www/html/pxe and will not handle DHCP, but can make sue of static DHCP configurations.
Ironic is just an API server at this point ( python based web service) that manages the above files, and that can also talk to the IPMI ports on my servers to wake them up and perform configurations on them.
I need to provide ISO images to Ironic so it can put the in the right place to boot them
Developer steps
I checked the code out of git. I am working off the master branch.
I ran tox to ensure the unit tests are all at 100%
I have mysql already installed and running, but with a Keystone Database. I need to make a new one for ironic. The database name, user, and password are all going to be ironic, to keep things simple.
CREATE USER 'ironic'@'localhost' IDENTIFIED BY 'ironic';
create database ironic;
GRANT ALL PRIVILEGES ON ironic.* TO 'ironic'@'localhost';
FLUSH PRIVILEGES;
Note that I did this as the Keystone user. That dude has way to much privilege….good thing this is JUST for DEVELOPMENT. This will be used to follow the steps in the developers quickstart docs. I also set the mysql URL in the config file to this
OK, so the first table shows that Ironic uses Alembic to manage migrations. Unlike the SQLAlchemy migrations table, you can’t just query this table to see how many migrations have been performed:
MariaDB [ironic]> select * from alembic_version;
+--------------+
| version_num |
+--------------+
| cf1a80fdb352 |
+--------------+
1 row in set (0.000 sec)
Running The Services
The script to start the API server is: ironic-api -d --config-file etc/ironic/ironic.conf.local
Looking in the file requirements.txt, I see that they Web framework for Ironic is Pecan:
This is new to me. On Keystone, we converted from no framework to Flask. I’m guessing that if I look in the chain that starts with ironic-api file, I will see a Pecan launcher for a web application. We can find that file with
Looking in that file, it references ironic.cmd.api, which is the file ironic/cmd/api.py which in turn refers to ironic/common/wsgi_service.py. This in turn refers to ironic/api/app.py from which we can finally see that it imports pecan.
Now I am ready to run the two services. Like most of OpenStack, there is an API server and a “worker” server. In Ironic, this is called the Conductor. This maps fairly well to the Operator pattern in Kubernetes. In this pattern, the user makes changes to the API server via a web VERB on a URL, possibly with a body. These changes represent a desired state. The state change is then performed asynchronously. In OpenStack, the asynchronous communication is performed via a message queue, usually Rabbit MQ. The Ironic team has a simpler mechanism used for development; JSON RPC. This happens to be the same mechanism used in FreeIPA.
Command Line
OK, once I got the service running, I had to do a little fiddling around to get the command lines to work. The was an old reference to
OS_AUTH_TYPE=token_endpoint
which needed to be replaces with
OS_AUTH_TYPE=none
Both are in the documentation, but only the second one will work.
I can run the following commands:
$ baremetal driver list
+---------------------+----------------+
| Supported driver(s) | Active host(s) |
+---------------------+----------------+
| fake-hardware | ayoungP40 |
+---------------------+----------------+
$ baremetal node list
curl
Lets see if I can figure out from CURL what APIs those are…There is only one version, and one link, so:
I found the following error from gpgv to be a little opaque:
gpgv: unknown type of key resource 'trustedkeys.kbx'
gpgv: keyblock resource '/home/lars/.gnupg/trustedkeys.kbx': General error
gpgv: Can't check signature: No public key
It turns out that’s gpg-speak for “your trustedkeys.kbx keyring doesn’t
exist”. That took longer to figure out than I care to admit. To get a key
from your regular public keyring into your trusted keyring, you can run
something like the following:
gpg --export -a lars@oddbit.com |
gpg --no-default-keyring --keyring ~/.gnupg/trustedkeys.kbx --import
After which gpgv works as expected:
$ echo hello world | gpg -s -u lars@oddbit.com | gpgv
gpgv: Signature made Mon 05 Oct 2020 07:44:22 PM EDT
gpgv: using RSA key FDE8364F7FEA3848EF7AD3A6042DF6CF74E4B84C
gpgv: issuer "lars@oddbit.com"
gpgv: Good signature from "Lars Kellogg-Stedman <lars@oddbit.com>"
gpgv: aka "keybase.io/larsks <larsks@keybase.io>"
Out of the box, OpenShift (4.x) on bare metal doesn’t come with any
integrated load balancer support (when installed in a cloud environment,
OpenShift typically makes use of the load balancing features available from
the cloud provider). Fortunately, there are third party solutions available
that are designed to work in bare metal environments. MetalLB is a
popular choice, but requires some minor fiddling to get it to run properly
on OpenShift.
To run MetalLB on Openshift, two changes are required: changing the pod
UIDs, and granting MetalLB additional networking privileges.
Pods get UIDs automatically assigned based on an OpenShift-managed UID
range, so you have to remove the hardcoded unprivileged UID from the
MetalLB manifests. You can do this by removing the
spec.template.spec.securityContext.runAsUser field from both the
controller Deployment and the speaker DaemonSet.
Additionally, you have to grant the speaker DaemonSet elevated
privileges, so that it can do the raw networking required to make
LoadBalancers work. You can do this with:
The docs here suggest some manual changes you can make, but it’s possible
to get everything installed correctly using Kustomize (which makes
sense especially given that the MetalLB docs already include instructions
on using Kustomize).
A vanilla installation of MetalLB with Kustomize uses a kustomization.yml
file that looks like this:
(Where configmap.yml and secret.yml are files you create locally
containing, respectively, the MetalLB configuration and a secret used to
authenticate cluster members.)
Fixing the security context
In order to remove the runAsUser directive form the template
securityContext setting, we can use the patchesStrategicMerge
feature. In our kustomization.yml file we add:
This instructs kustomize to replace the contents of the securityContext
key with the value included in the patch (without the $patch: replace
directive, the default behavior is to merge the contents, which in this
situation would effectively be a no-op).
We can accomplish the same thing using jsonpatch syntax. In this case,
we would write: